设计模式:六大设计原则
学习软件设计模式,需要了解使用设计模式的目的,23种设计模式是对设计模式使用场景进行分类再抽象的方法论,遵循了基本的设计原则。
学习软件设计模式,还需要了解其设计的原则,需要了解软件的可维护性和可复用性。
另:设计是有限度的,不能无限地考虑未来的变更情况,否则会陷入设计的泥潭中难以自拔。
设计模式
模式是可重复的解决方案。
在编程实践中发现有些问题是重复出现的,虽然场景各有不同,但是问题的本质是一样,而解决这些问题的方式也是可以重复使用。提炼出这些可重复使用的编程方法称为设计模式。
设计模式的精髓就是对多态的灵活应用。
可维护与可复用
可维护性
导致一个软件设计的可维护性较低,也就是说随着性能和需求要求的变化而 腐烂 的真正原因有四个:过于僵硬(Rigidity),过于 脆弱(Fragility),复用率低(Immobility),粘度过高(Viscosity)—–Rober C. Martin。
过于僵硬
难以加入一个新的功能,哪怕很少的都很困难,因为可能波及很多其它模块。使得一个起初只需几天的工作,最后演变成持续很长时间甚至个把月的连续改造。
此缺陷使得不敢轻易加入新功能,导致软件一旦做好,就不能增加新功能的僵硬化的情况。
过于脆弱
软件系统在修改已有代码时过于脆弱。一个地方的修改,导致看上去没什么关系的另一个地方发生故障。尽管在修改之前,可能会竭尽所能预测可能的故障点,但在修改完成之前,工程师甚至无法预测可能会波及到的地方。
这种一碰就碎的情况,造成软件系统过于脆弱。
复用率低
复用:指软件的组成部分,可以在同一个项目的不同地方甚至另一个项目中重复使用。
复用率低,一些代码,函数,模块的功能可以在新的模块,或新的系统中使用,而这些已有的代码依赖于一大堆其他的东东西,以至于很难将它们分开。最后就是不去碰这些东西,而是重新写自己的代码,或使原始的复制粘贴的办法。
这样的系统就有复用率低的问题。
黏度过高
黏度过高 在软件工程里也称为 高耦合,软件开发追求 高内聚、低耦合。
如果一个改动没有沿用原始的设计,而是在模块中搭建了一个短路桥,或在通用的逻辑中制造一个特例,以便解决眼前的需要,这样就牺牲了中长期的利益。这样的改动会使系统黏度过高,会诱使维护它的程序员采取错误的维护方案,相对的并惩罚采取正确维护方案的程序员。
可复用性
传统的复用
- 代码的剪贴复用:一段代码在各个地方被引用,甚至一段代码被剪贴到其它需要的地方。
- 算法的复用:各种算法比如排序算法得到了大量的研究。现在通常的做法是在得到了很好的研究的各种算法中选择一个。这就是算法的复用。
- 数据结构的复用:如队,栈,Hash 表等数据结构得到了很好的研究,选择合适的数据结构就是复用。
传统的复用集中在 函数、算法、数据结构 等具体实现细节上。
面向对象设计的复用
Java 这样的面向对象的语言中,数据的抽象化、继承、封装和多态性是几项非常重要的语言特性,这些特性可以使得一个系统可以在更高的层次上提供可复用性。
数据的抽象化和继承关系使得概念和定义可以复用;多态使得实现和应用可以复用;而抽象和封装可保持和促进系统的可维护性。
面向对象设计的复用集中在最重要的含有宏观业务逻辑的抽象层次上。
设计的目标
一个好的系统设计应有如下的特质:可扩展性(Extensibility),灵活性(Flexibility),可插入性(Pluggability)。—- Perter Coad。
可扩展性
新的功能可以很容易加入到系统中,就是可扩展性。这是 过于僵硬 的反面。
灵活性
可以允许代码修改平稳地发生,而不会波及到很多其他的模块,这就是灵活性。这是 过于脆弱 的反面。
可插入性
可以很容易地将一个类抽出去,同时将另一个有同样接口的类加入进来,就这是可插入性。这是 黏度过高 的反面。
六大设计原则
设计原则是在做软件设计时的重要参考,其目的是尽可能提高程序的可维护性和可复用性。
在面向对象的设计里面,可维护性 与 可复用性 是以设计原则和设计模式为基础的。
可扩展性:由 开闭原则、里氏替换原则、依赖倒转置原则 和 组合/聚合复用原则 所保证。
灵活性:由 开闭原则、迪米特法则、接口隔离原则所保证。
设计原则首先都是复用的原则,遵循这些设计原则可以有效地提高系统的复用性,同时提高系统的可维护性。
软件设计模式的七大原则总结:
| 设计原则 | 归纳 | 目的 |
|---|---|---|
| 开闭原则 | 对扩展开放,对修改关闭 | 降低维护带来的新风险 |
| 依赖倒置原则 | 高层不依赖低层,要具体依赖抽象,面向接口编程 | 更利于代码结构的升级扩展 |
| 单一职责原则 | 一个类只干一件事,仅有一个引起它变化的原因 | 便于理解,提高代码的可读性 |
| 接口隔离原则 | 一个接口只干一件事,接口要精简单一 | 功能解耦,高聚合、低耦合 |
| 迪米特法则 | 一个类应当保持对其类最少的了解,不该知道的不要知道 只和朋友通信,不和陌生人说话 |
减少代码臃肿 |
| 里氏替换原则 | 凡是基类型使用的地方,子类型一定适用; 可以扩展基类,但子类的修改不能影响基类 |
防止继承泛滥 |
注意:设计原则是重要参考,不是必须遵循的法则。在实际开发中,要综合考虑项目的实际情况,人员技能水平,时间成本,质量要求等,要在适当的场景遵循设计原则,这体现的是一种平衡取舍,可以帮助我们设计出更加优雅的代码结构。
开放封闭原则
开-闭原则(OCP:Open-Close-Principle):一个软件实体应当对扩展开放,对修改关闭,即在不被修改的前提下被扩展。
抽象
开-闭原则的关键在于抽象化,抽象层封装与商业逻辑有关的重要行为,这些行为的具体实现由实现层给出。
抽象层不能再修改,但允许扩展系统的实现层,这样系统就有一定的稳定性和延续性。
抽象的行为由具体实现层提供,这样就提供了新的行为,满足对软件的新需求,易于扩展且具有一定的灵活性和适应性。
从开-闭 原则可以看出 面向对象设计 的重要原则是创建抽象化,并且从抽象化导出具体化。具体化可以给出不同的版本,每一个版本都给出不同的实现。
对可变性的封装
开-闭原则如果从另一个角度来讲述,就是所谓的 对可变性的封装原则,讲的是找到一个系统的可变因素,将之封装起来。
对可变性的封装原则:与通常将焦点放在什么会导致设计改变的思考方式正好相反,这一思路考虑的不是什么会导致设计改变。而是考虑你允许什么发生变化,而不让这一变化导致重新设计
对可变性的封装原则意味着两点:
一种可变性不应当散落在代码的很多角落里,而应当被封装到一个对象里面。同一种可变性的不同表象意味着同一个继承等级结构中的具体子类。
继承应当被看做是封装变化的方法,而不应该被认为是从一般的对象生成特殊的对象的方法。
一种可变性不应当与另一种可变性混合在一起,表现上是继承不该超过两层,否则就意味着将两种不同的可变性混合在了一起。
【GOF95】指出,对可变性的封装原则 实际上是设计模式的主题。换句话说,所有的设计模式都是对不同的可变性的封培训,从而使系统在不同的角度上达到 开-闭原则的要求。
与其它原则的关系
里氏替换原则:指任何基类可以出现的地方,子类一定可以出现。
里氏替换原则是对 开-闭 原则的补充。实现 开-闭 原则的关键步骤是抽象化。而基类与子类的继承关系就是抽象化的具体体现,所以里氏替换原则是对实现抽象化的具体步骤的规范。
一般而言,违返里氏替换原则,也违背 开-闭 原则,反过来并不一定成功。
依赖倒转置原则:指要依赖于抽象,不要依赖于实现。
看上去 依赖倒转置 原则与 开-闭原则 很类似,实现上,他们之间是 目标 和 手段 之间的关系。开-闭原则是目标,而达到这一目标的手段是 依赖倒转置原则。
换句话说,要想实现 开-闭原则,就应当坚持 依赖倒转置原则。违反依赖倒转置原则,就不可达到 开-闭 原则的要求。
合成/聚合复用原则:指的是要尽量使用 合成/聚合,而不是继承关系达到复用的目的。,
合成/聚合复用原则是与 里氏替换原则相辅相成的,两者又都是对实现 开-闭原则的具体步骤的规范。前者要求设计师首先考虑 合成/聚合关系,后者要求在使用继承关系时,必须确定这个关系是符合一定条件的。
遵守 合成/聚合 复用原则是实现 开-闭 原则的必要条件;违反这一原则就无法使系统实现 开-闭 原则这一目标。
迪米特法则:又叫最少知识原则,指一个软件实体应当于尽可能少的其他实体发生相互作用
即尽可能保持模块相对独立,在需要修改时不会将修改的压力传递给其他的模块。
也就是说,一个遵守迪米特原则设计出来的系统在功能需要扩展时,会相对更容易地做到对修改的关闭。也就是说,迪米特法则是一条通向 开-闭 原则的道路。
接口隔离原则:指应当为客户端提供尽可能少的单独的接口,而不是指供大的总接口。
接口隔离原则 与 广义的迪米特法则 都是对一个软件实体与其他的软件实体的通信的限制。
广义的迪米特法则要求尽可能限制通信的宽度和深度。接口隔离原则所限制的是通信的宽度,也就是说通信应当尽可能地窄。
遵特接口隔离原则与迪米特法则,会使一个软件系统在功能扩展的过程中,不会将修改的压力传递到其他的对。
在其它设计模式中的体现
开-闭 原则要求系统允许新的功能加入系统中,而无需对现有代码进行修改。
简单工厂模式:对产品的消费角色是成立的,但对于工厂角色是不成立的。每次增加一个新的增品,都需要修改工厂角色。但是产品的消费者则可以避免修改。
工厂方法模式:具体工厂类都有共同的接口,它们生产出很多处于一个等级结构中的产品对象。该模式允许向系统加入新的产品类型,而不必修改已有的代码,只需再加入一个相应的新的具体工厂类即可,即完全支持 开-闭 原则。
抽象工厂模式:抽象工厂模式封装了产品对象家族的可变化性,从而一方面可以使系统动态地决定将哪一个产品族的产品实例化,另一方面可以在新的产品对象引进到已有的系统中时不必修改已有的代码。即该模式可以维持系统的 开-闭 性。
建造模式:建造模式封装了建造一个内部结构的产品对象的过程,因此是向产品内部表象的改变开放的。
桥接模式:桥接模式是对可变性的封装原则的极好例子。在桥接模式中,具体实现类代表不同的实现逻辑,但是所有的具体实现类又有共同的接口。新的实现逻辑可以通过创建新的具体实现类加入到系统中。
门面模式:假设一个系统与另一个子系统耦合在一起,后来又必须换成另一个子系统,那么门面模式便可以发挥门面模式和适配器模式两种作用,将新的子系统仍然与本系统耦合在一起。使用门面模式便可以改变子系统内部功能而不影响到客户端。
调停者模式:调停者模式使用一个调停者对象协调各个同事对象的相互作用,这些同事对象不再发生直接的相互作用。调停者模式类图类似于一个星型网络图。
使用该模式,如果有新的同事对象添加到系统中来的时候,这些已有的同事对象都不会受到任何影响,但调停者本身却需要修改。即 调停者模式以一种不完美的方式支持 开-闭 原则。
访问者模式:访问者模式使得在节点中加入新的方法变得很容易,仅仅需要在一个新的访问者类中加入此方法就可以了,但是访问者模式不能很好地处理增加新节点的情况。也就是说,访问者模式提供了倾斜的可扩展性设计:方法集合的可扩展性和类集合的不可扩展性。
也就是说,访问者模式的使用可以使一个节点系统对方法集合的扩展开放。
迭代子模式:迭代子模式将访问聚集元素的逻辑封装起来,并且使它独立于聚集对象的封装。这就提供了聚集逻辑与迭代逻辑独立演变的空间,使系统可以在无需修改消费迭代子的客户端的情况下,对聚集对象的内部结构进行功能扩展。
单一职责原则
定义
单一职责原则:就一个类而言,应该仅有一个引起它变化的原因,即该类应该只有一个职责。
该原则由罗伯特·C·马丁(Robert C. Martin)于《敏捷软件开发:原则、模式与实践》一书中给出的。马丁表示此原则是基于【汤姆·狄马克】(Tom DeMarco)和Meilir Page-Jones的著作中的【内聚性】原则发展出的。
如果一个类承担的职责过多,就等于把这些职责耦合在一起了,一个职责的变化可能会削弱或者抑制这个类完成其他职责的能力。这种耦合会导致脆弱的设计,当发生变化时,设计会遭受到意想不到的破坏。而如果想要避免这种现象的发生,就要尽可能的遵守单一职责原则。
则原则的核心就是解耦和增强内聚性。
职责扩散
只要是程序设计人员都清楚应该写出高内聚低耦合的程序,但是很多耦合常常发生在不经意之间,其原因就是:
职责扩散:因为某种原因,某一职责被分化为颗粒度更细的多个职责了。
解决该问题的方法就是:遵守单一职责原则,将不同的职责封装到不同的类或模块中。
优缺点
优点
- 降低类的复杂度,一个类只负责一个职责,该类的单一职责逻辑就比多职责逻辑简单多了。
- 提高类可维护性,单一职责易于维护,降低了变更引起的风险。
缺点
如果职责化分的很细的话,每个职责都由一个单独的类负责,可能会导致类膨胀反而变的复杂。
简单的例了,一个家庭有很多每天必做的事,洗衣,拖地,做饭,不可能每件事都雇一个佣人,只有单某件事扩散变得复杂了,然后再把该事件独立出来由一个单独的人负责。
里氏替换原则
子类可替换基类
里氏替换原则:是对子类型的特别定义,可以描述为 派生类(子类)对象可以在程序中代替其基类(超类)对象。
指一个软件实体如果使用的是一个基类的话,那么一定适用于其子类,而且它根本不察觉出基类对象和子类对象的区别。
里氏替换原则 要求凡是基类型使用的地方,子类型一定适用,因此子类必须具备基本类型的全部接口。或者说,子类型的接口必须包括全部的基类型的接口,而且还有可能更宽。
假设一个基类 Base ,另一个是其子类 Sub。那么一个方法如果可以接受一个基类对象 b 的话:method1(Base b),那么它必解码器可以接受一个子类对象 s,即也可以有 method1(s)。
在编译时期,Java 语言编译器会检查一个程序是否符全里氏替换,这是一个无关实现,纯语法意义上的检查。
例如子类私有化了基类的公共方法,Java 编译就会报错。这是因为客户端完全有可能调用基类的公开方法。如果以子类型代之,这个方法就不能被调用了,违反了里氏替换原则。
注意:反过来是不行的,即一个软件实体使用的是子类的话,那么它不一定适用于基类。
里氏替换原则 是继承复用的基石。只有当派生类可以替换掉基类,软件单位的功能不会受到影响时,基类才能真正被复用,而派生类也才能够在基类的基础上增加新的行为。
总结一句话就是:尽量不要继承可实例化的父类,而是要使用基于抽象类和接口的继承。
在其它设计模式中的体现
策略模式:如果有一组算法,将每一种算法封装起来,使它们可以互换。封装易理解,要实现所有的算法可以互换,则需要将所有的具体策略角色放到一个类型等级结构中,使它们拥有共同的接口。这种互换性依赖的是对 里氏替换原则的遵守。
1
AbstractStrategy s = new ConcreteStrategyA();
上面示例可以看出,客户端依赖于基类类型,而变量的真实类型则是具体策略类。这种具体策略角色可以 即插即用(Pluggable)的关键。
合成模式:通过使用树结构描述整体与部分的关系,从而可以将单纯属元素与复合元素同等看待。
由于单纯元素和复合元素都是抽象元素角色的子类,因此两者都可以替换抽象元素出现的任何地方。
里氏替换原则 是合成模式能够成立的基础。
代理模式:给某一个对象提供一个代理对象,并由代理对象控制对原对象的引用 。
代理模式能够成立的关键,就在于代理模式(代理对象)与真实主题模式(原对象)都是抽象主题角色的(抽象类)的子类。客户端只知道抽象类,而代理对象可以替换抽象类出现在任何需要的地方,而将真实主题隐藏在幕后。
里氏替换原则是代理模式能够成产的基础。
从代码重构的角度理解
里氏替换原则讲的是基类与子类的关系。只有当这种关系存在时,里氏替换关系才存在;反之则不存在。
如果有两个具体类 A 和 B 之间违反了里氏替换原则的设计,则重构方案可以如下:
- 创建一个新的抽象类 C,作为两个具体类的基类,将 A 和 B 的共同行为移动到 C 中,从而解决 A 和 B行为不完全一致的问题。
- 从 B 到 A 的继承关系改写为委派关系。
依赖倒转原则
实现 开-闭 原则的关键是 抽象化,并且从抽象化导出具体化实现。如果说 开-闭 原则是面向对象设计的目标的话,依赖倒转 原则就是这个面向对象设计的主要机制。
在Java中,抽象就是指接口或者抽象类,两者都是不能直接被实例化的;细节就是实现类,实现接口或者继承抽象类而产生的就是细节,以关键字 new 产生对象。
Robert C. Martin 在他的著作《敏捷软件开发:原则、模式与实践》中有这样的两句描述:
- High-level modules should not depend onlow-level modules. Both should depend on abstractions.(高层模块不应该依赖于低层模块,二者都应该依赖于抽象)
- Abstractions should not depend upondetails. Details should depend upon abstractions.(抽象不应该依赖于具体实现细节,而具体实现细节应该依赖于抽象)
即,模块类之间的依赖是基于抽象类的,实现类之间不能有直接的依赖关系,其依赖关系是通过接口或者抽象类产生的。其核心思想是:要面向接口编程,不要面向实现编程。
什么是依赖倒转
依赖倒转原则讲的是:要依赖于抽象,不依赖于具体(细节)。把抽象层依赖于具体层这种错误的依赖关系倒转过来。
不同的表述:
第一种表述:要针对接口编程,不要针对实现编码。
第二种表述,GOF95 一书所强调的:针对接口编程的意思是,应当使用 Java 接口和抽象类进行变量的类型声明、参量的类型声明,方法的返还类型声明,以及数据类型的转换等。
不要针对实现编程的意思是说,不应当使用具体类进行变量的类型声明,参量的类型声明,方法的返还类型声明,以及数据类型的转换等。
要保证做到这一点,一个具体 Java 类应当只实现 Java 接口和抽象 Java 类中声明过的方法,而不应当给出多余的方法。倒转依赖关系强调一个系统内的实体之间关系的灵活性。基本上,如果设计师希望遵守 开-闭原则,那么 依赖倒转 原则便是达到要求的途径。
抽象层:包含系统宏观层面的逻辑,对整个系统来说是重要的战略性决定,是较为稳定的,是必然性的体现。
实现层:包含一些次要的与实现有关的算法和业务逻辑,是战术性的决定,带有相当大的偶然性选择。
基于复用与维护的【倒转】,应当将复用的重点放在抽象层次上。如果抽象层的模块相对独立于具体实现层模块的话,那么抽象层的模块的复用便相对较为容易。
三种耦合关系
在面向对象的系统里,两个类之间可以发生三种不同的耦合关系:
- 零耦合(Nil Coupling)关系:如果两个类没有耦合关系,就称之为零耦合。
- 具体耦合(Concrete Coupling)关系:具体性耦合生在两个具体的(可实例化的)类之间,经由一个类对另一个具体类的直接引用造成。
- 抽象耦合(Abstract Coupling)关系:
变量的静态类型与实际类型
变量被声明时的类型叫做变量的静态类型,或叫明显类型。变量所引用的对象的真实类型叫做变量的 实际类型。
示例如下:List employees = new Vector(); List 是变量的静态类型,Vector 是变量的实际类型。
引用对象的抽象类型
在很多情况下,一个Java 程序需要引用一个对象,如果一个被引用的对象存在抽象类型,就就当在任何引用此对象的地方,声明时使有抽象类型作为变量的静态类型,包括参量的类型声明,方法返还类型的声明。这就是针对接口编程的含义。
实现依赖倒转原则
以抽象方式耦合是依赖倒转原则的关键。由于一个抽象耦合关系总要涉及具体类从抽象类继承,并且需要保证在任何引用到基类的地方都可以改换在其子类,因此,里氏替换原则是依赖倒转原则的基础。
在抽象层次上的耦合虽然有灵活性,但也额外带来了复杂性。基某些情况下,如果一个具体类发生变化的可能性很小,那么抽象耦合能发挥的好处便十分有限,这时使用具体耦合反而会更好。
依赖倒转原则是 OO 设计的核心原则,设计模式的研究和应用是以依赖倒转原则为指导原则的。
模板方法模式
模板方法模式是依赖倒置原则的具体体现。在模板方法模式里面,有一个抽象类将得要的宏观逻辑以具体方法以及具体构造方法的形式实现,然后声明一些抽象方法来迫使子类实现剩余的具体细节上的逻辑。不同的子类可以以不同的方式实现这些抽象方法,而从对剩余的逻辑有不同的实现。
具体子类不能影响抽象类的达能观逻辑,而抽象逻辑的改变则会导致细节逻辑的改变。
迭代子模式
迭代子模式用一个工厂方法向客户端提供一个聚集的内部迭代功能,客户端得到的是一个Iterator 抽象类型,并不知道迭代子的具体实现以及聚集对象的内部结构。聚集的内部结构的改变就不会涉及到客户端,从而实现了对抽象接口的依赖。
接口隔离原则
接口隔离原则:使用多个专职的接口比使用单一庞大的臃肿总接口要好。即一个类对另外一个类的依赖性应当是建立在最小的接口上的。即接口尽量细化,保证接口的纯洁性。
接口隔离
每一个接口相当于代表一个角色,实现一个接口的对象,在它的整个生命周期中都扮演这个角色,因此将角色区分清楚就是系统设计的一个重要工作。
因此,一个符合逻辑的推断,不应当将几个不同的角色都交给同一个接口,而应当交给不同的接口。准确而恰当地划分角色以及角色所对应的接口,是面向对象的设计的一个重要的组成部分。若将没有关系的接口合并在一起,形成一个臃肿的大接口,是对角色和接口的污染。
接口隔离原则是对接口进行规范约束,其包含以下4层含义:
接口要尽量小
接口隔离原则的核心定义,不出现臃肿的接口。但注意,尽量小也是有限度的,要从业务逻辑上考虑,接口控制到最小的业务单元就足够了。
根据接口隔离原则,拆分接口时中,首先必须满足单一职责原则。
接口要高内聚
即要提高接口、类、模块的处理能力,减少对外的交互和依赖。要在接口中尽量少公布 public 方法,接口是对外的承诺,承诺越少对系统的开发越有利,变更的风险也越少,同时也利于降低成本。
提供定制服务
一个系统或系统模式之间必然会有耦合,就会有相互访问的接口。在设计时就需要为各个访问者定制服务,即为满足差异化的访问,单独为一个个体提供优良的服务。
仅提供客户需要的方法,不提供不需要的方法。
接口有限粒度
接口的设计粒度越小,系统越灵活,但同时也会带来结构的复杂化,增加开发难度,降低可维护性。所以接口设计一定要注意适度,这只能根据经验和常识判断了,没有固化或可测量的标准。
接口隔离原则 也是符合 迪米特法则 的。
接口隔离优点
接口隔离原则也适用于定制服务,即仅提供客户需要的方法,而不提供不需要的方法。
提高系统的可维护性:向客户端提供的 public 接口是一种承诺,一个 public 接口一旦提供,就很难撤回,过多的承诺会给系统的维护增加不必要的负担。
如果提供服务的接口出现变化,设计师知道具体是那些级别的接口会影响到对应的客户端,哪些不会受到影响。
接口隔离示例
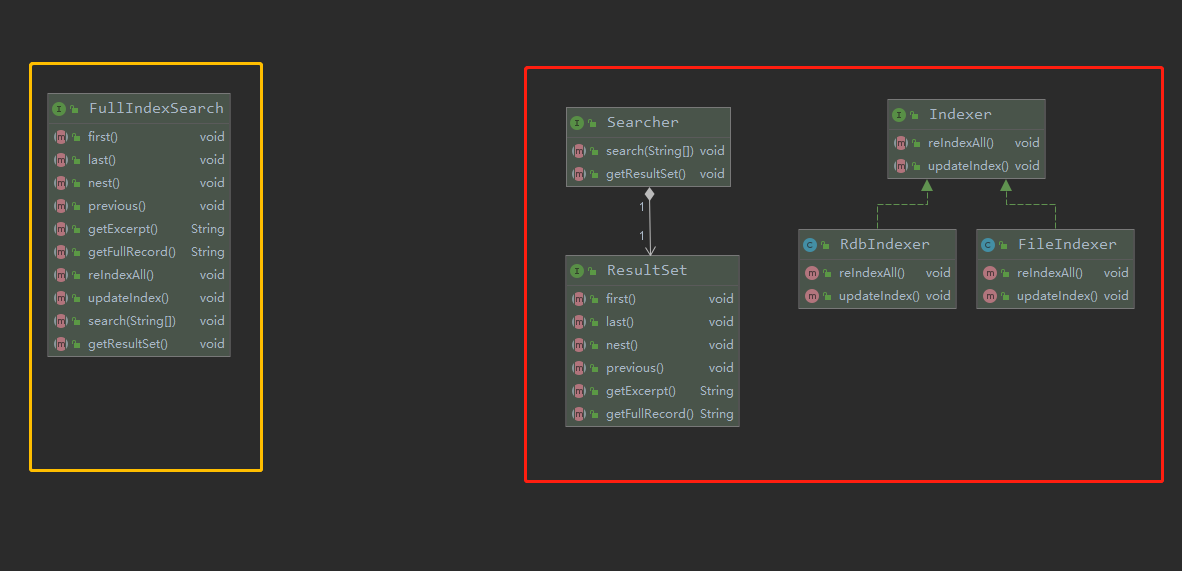
全文查询引擎的系统的接口设计。
不好的例子:一个接口负责所有的操作,从提供搜索功能到建立索引,甚至包括搜索结果集合的功能均在一个接口内提供。这就是典型的接口角色划分不清的问题,把不同角色的功能堆放在一起,违反了角色分离原则。
改进:对该接口进行我角色划分,拆分成:搜索器角色,索引生成器角色,搜索结果集角色;明确各个角色的职能范围。
搜索器角色 Searcher 返回一个 ResultSet 对象,Searcher 与 ResultSet 是依赖聚合的关系。
迪米特法则
迪米特法则 又称为 最少知识原则:就是说,一个对象应当对其它对象有尽可能少的了解。
迪米特法则的初衷在于降低类之间的耦合。由于类尽量减少对其他类的依赖,因此,很容易使得系统的功能模块独立,相互之间不存在或存在很少的依赖关系。
众多表述
迪米特法则 有多种表述,下面是众多的表述中较有代表性的几种:
- 只与你直接的朋友通信(Olny talk to your immediate friends)
- 不要跟 “陌生人” 说话(Don’t talk to strangers)
- 每一个软件单位对其他单位都只有最少的知识,而且局限于那些与本单位密切相关的软件单位。
朋友圈定义
- 当前对象本身(this)
- 以参量形式传入到当前对象方法中的
- 当前对象的实例变量直接引用的对象
- 当前对象的实例变量如果是一个聚集,那么聚集中的元素也都是朋友
- 当前对象所创建的对象
任何一个对象,如果满足上面的条件之一,就是当前对象的 “朋友”;否则就是 “陌生人”。
设计示例
一个示例,有 Friend,Someone,Stranger 三个类,其中 Someone 与 Friend 是朋友,Friend 对象作为 Someone 构造方法的传入参数。
迪米特法则的改造示例:
1 | public class Someone { |
狭义的迪米特法则的缺点
遵循狭义的迪米特法则会产生一个明显的缺点:会在系统里造出大量的小方法,散落在系统的各个角落。这些方法仅仅是传递间接的调用,与系统的业务逻辑无法。容易造成迷惑和困扰。
遵循类之间的迪米特法则会使一个系统的局部设计简化,但也会造成系统的不同模块之间的通信效率降低,也会使系统的不同模块之间不容易协调。
与依赖倒转置原则互补使用
为了克服狭义的迪米特法则的缺点,可以使用依赖倒转置原则,引入一个抽象的类型引用 “抽象随生人” 对象,使 “抽象陌生人” 变成 “某人” 的朋友。
1 | /** |
广义的迪米特法则
迪米特法则所谈论的,实际是对象之间的信息流量,流向以及信息的影响控制。
在软件系统中,一个模块设计得好不好的最主要,最重的标志,就是该模块在多大的程度上将自己的内部数据和其他与实现有关的细节陷藏起来。
一个设计很好的模块可以将它所有的实现细节隐藏起来,彻底地将提供给外界的 API 和自己的实现分隔开来。使模块与模块之间可以仅仅通过彼此的 API 相互通信,而不理会模块内部的工作细节。这一概念就是 信息的隐藏 或者叫做 封装,也就是大家熟悉的面向对象软件设计特征之一。
信息的隐藏(封装)非常重要的原因在于,它可以使各个子系统之间脱耦,从而允许它们独立地被开发,优化,使用,阅读以及修改。
这种脱耦化可以有效地加快系统的开发过程,因为可以独立地同时开发各个模块。它可以使维护过程变得容易,因为所有模块都容易读懂,特别是不必担心对其他模块的影响。
信息的隐藏并不能带来更好的性能,但它可以使性能的有效调整变得容易。一旦确认某一个模块是性能的障碍时,设计人员可以针对这个模块本身进行优化,而不必担心影响到其他的模块。
信息的隐藏可以促进软件的复用。由于每一个模块都不依赖于其他模块而存在,因此每一个模块都可以独立地在其他的地方使用。一个系统的规模越大,信息的隐藏就越是重要,而信息隐藏的威力也就越明显。
迪米特法则运用注意事项
迪米特法则的主要用意是控制信息的过载。在将迪米特法则运用到系统设计中时,要注意下面的几点:
在类的划分上,应当创建有弱耦合的类。
类之间的耦合越弱,就越有利于复用。一个处在弱耦合中的类一旦被修改,不会对有关系的类造成波及。
在类的结构设计上,每一个类都应当尽量降低成员的访问权限(Accessibility)。
换而言之,一个类包装好自己的 private 状态。一个类不应当 public 自己的属性,应当提供取值或赋值方法让外界间接访问自己的属性。
在类的设计上,只要有可能,一个类应当设计成不变类。
在对其他类的引用上,一个对象对其对象的引应当降到最低。
广义迪米特法则在类的设计上的体现
优先考虑将一个类设置成不变类
Java 提供了很多不变类,如:String,BigInteger,BigDecimal 等封装类都是不变类。不变类易于设计,实现和使用。
在设计任何一个类的时候,首先考虑这个类的状态是否需要改变。即便一个类必须是可变类,在给它的属性设置赋值方法的时候,也要保持吝啬的态度。除非真的需要,否则不要为一个属性设置赋值方法。
尽量降低一个类的访问权限
在满足一个系统对这个类的需求的同时,应当尽量降低这个类的访问权限(accessibility)。对于项级(top-level)的类来说,只有两个可能的访问权限等级:
package-privage:default,包路径下可访问,这是默认的访问权限,即只能从当前库访问。
package-private 的好处是,一旦这个类发生修改,那么受影响的客户端必定是在这个库内部。由于一个软件包往往有它自己的库结构,因此一个访问权限为 package-private 的类是不会被客户应用程序使用的,这意味着软件提供商可以自由地决定修改这个类,而不必担心对客户的承诺。
public:public 修饰的类,可以从当前库和其他库访问它。客户应用就有可能会使用这个类,一旦这个类有更新或删除,就可能造成客户的程序停止运行的情况。
如果一个类可以设置成为 package-private 的,那么就不应当将它设置成为 public 。
谨慎使用 Serializable 接口
一个类如果实现了 Serializable 接口的话,客户端就可能将这个类的实例序列化,然后再反序列化。
由于 序列化 和 反序列化涉及到类的内部结构。如果这个类的内部 private 结构在一个新版本中发生变化的话,那么客户端可能会根据新版本的结构试图将一个老版本的 序列化 结果 反序列化,这会导致失败。
也就是说,为防止这种情况发生,软件提供商一旦将一个类设置成为 Serializable 的,就不能再在新版本中修改这个类的内部结构,包括 private 的 方法和句段。因此,除非必要,不要使用 Serializable。
尽量降低成员的访问权限
类的成员包括:属性、方法、嵌套类,嵌套接口等。一个类的成员可以有四种不同的访问权限
| 访问权限 | 同一个类 | 同一个包 | 不同包的子类 | 不同包的非子类 | 描述 |
|---|---|---|---|---|---|
| public | √ | √ | √ | √ | 开放的访问权限 |
| protected | √ | √ | √ | 保护访问权限,为继承而设计 当前类和子类可访问 |
|
| default(默认) | √ | √ | 默认的,没有权限修饰符 又称 package-private 同包内私有,同包的类可以访问 |
||
| private | √ | 私有权限,只允许本类内访问 |
注:其中 private 和 protected 不能修饰的类接口,否则编译就会报“modifier private not allowed here”
作为一条指导原则,应将访问权限控制在有限的范围内,并且是根据需要逐步开放,而不是一次性全部对外开放。一旦设置成 public,那么就可能被任何类访问。这对一个软件提供商来说,意味着客户程序可能使用该方法,因此在所有以后的版本中都要承诺不改变这个方法的特征,就变成了对外的一种承诺,这个成本可能是非常高昴的。
因此,将 private 或 package-private 方法改为 protected 或者 public,必须慎之又慎。
广义迪米特法则在代码层次上的实现
Java 语言允许一个变量在任何地方声明,即任何可以有语句的地方都可以声明变量,相对于 C语言要求所有局域变量都在一个程序块的开头声明,这样做的意义深远,是被很多人忽略的。
在需要一个变量的时候才声明它,可以有效地限制局域变量的有效范围。一个变量如果仅仅在块的内部使用的话,就应当将这个变量在程序块的内部使用它的地方声明,而不是放到块的外部或者块的开头声明。这样做有两个好处:
程序员可以很容易读懂程序。
否则,程序员需要反复对照使用变量的语句和变量的声明语句才能将变量的使用与声明对上号。并且局部变量随语句块的的修改是可见的,而不会散落在其它地方,当不再被使用时也没有人留意将其删除。
如果一个变量是在需要它的程序块的外部声明的,那么当这个块还没有被执行时,这个变量就已经被分配内存了;而这个程序块已经执行完毕后,这个变量所占据的内存空间还没释放,这显然是不好的。