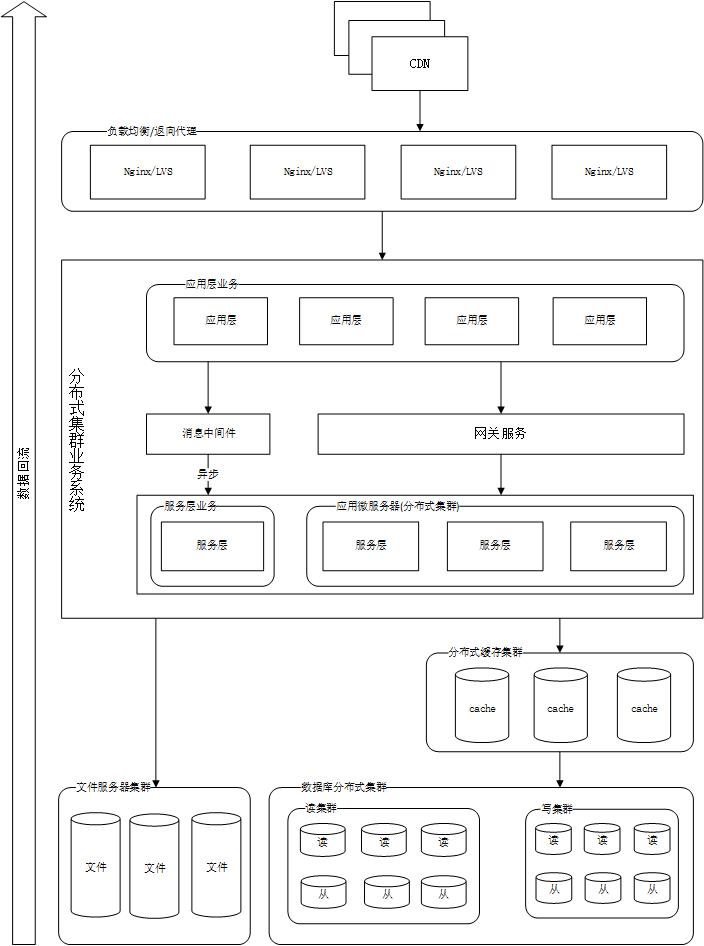
大型网站架构演化历程
大型网站应用是随着业务的扩张发展从小型网站演化而来,适合的架构才是最好的架构,满足业务需求,没有资源浪费。在互联网行业,技术为业务服务,架构演进由业务需求驱动。
大型互联网应用特点
大型互联网应用特点:高并发、大流量;高可用(7*24小时);海量数据;用户分布广,网络复杂,环境复杂;安全环境恶劣;需求多变,快速迭代,发布频繁;渐近式发展。
基于以上特点,对大型互联网应提出了要满足高可用、高性能、易扩展、可伸缩、安全的的需求;驱动了大型互联网架构的演进。
架构演进方式
单机集中式
一台服务器,应用程序、数据库、文件等所有资源都在这一台服务器上。
有些小型系统、企业内部系统、传统行业的一些管理系统基于此方式。
应用与数据分离
随着业务的发展,一台服务器不能满足需求,性能变差,存储空间不足,这时就可以将应用程序与数据分离。
分离后使用三台服务器:应用服务器,文件服务器,数据库服务器。这三台服务器可以配置不同的硬件资源,承担不同的服务角色,改善网站的并发处理和存储空间。
使用缓存提高性能
系统出现了热点数据,80%的访问集中在一小部分的热点数据上,把这一小部分数据缓存起来,干涩改善数据读写性能,提高访问速度。
网站缓存分两种:应用服务器上的本地缓存和专门的分布式缓存服务器上的远程缓存。
本地缓存:如系统初始化或动态更新热点数据到系统缓存,Java系统可使用内部简单缓存(HashMap)或集成 Ecache 等。内部缓存受限于服务器的内存容量,缓存数据量有限。
远程缓存:部署专门的远程大内存缓存服务器,如 Redis, Memcached 等,可单机部署,也可集群部署。
应用服务器集群布署
当一台应用服务器处理能力和空间不足时,增加一台服务器搭建集群分担访问压力,通过负载均衡调度器(反向代理),将请求分发到应用服务器集群,应用服务器的负载压力就不会成为整个系统的瓶颈。
数据库读写分离
当网站业务达到一定规模后,数据库会因为负载过高,硬盘有限的I/O性能而成为网站的瓶颈。
数据库读写分离,配置主成同步和主从热备,可以改善数据库负载压力。
部署到CDN
CDN是基于缓存原理,将资源部署到离用户最近的机房,用户从最近的电信运营商机房获取数据。如一些静态资源,门户和二级门户等放到CDN上。
分布式文件系统
大型网站业务持续增长,图片和各种类型的文件快速增长,单一的文件服务器不足以满足需求,这时需要使用分布式文件数据库(FastDFS,MongoDb等)。
分布式数据库
当数据库数据规模非常庞大时,需要对数据库表进行拆分,数据库拆分式建议优先按业务垂直拆分表,将业务表分配到不同的数据库上;当业务分库数据非常大时,再对业务分库里的表数据进行水平拆分。
NoSQL和搜索引擎
网站的业务越来越复杂,大量的数据检索需求也越来越复杂,这时可采用非关系数据库如NoSQL和搜索引擎(Solr,ElasticSearch),提高数据查询检索的效率,降低直接访问数据库的负载压力。
业务拆分
将整个大型系统按业务进行拆份,分成不同的产品线,如电商网站可执分成门户、订单、支付、购物车等子系统,访问自己的数据库,通过远程调用完成整体的业务流程,构成完整的系统,分归于不同业务团队负责。
分布式微服务
系统越来越大,业务拆分越来越小,抽取公共基础服务,将业务独立部署。现在已有现成的技术来支持分布式微服务系统(Dubbo, Zookeeper, Spring Boot, Spring Cloud, Docker, kubernetes等)