Spring Cloud(十六):消息驱动-Stream 概念、绑定器、属性
Spring Cloud Stream 是一个用于构建消息驱动的微服务应用的框架。Spring Cloud Stream 构建于Spring Boot之上,用于创建独立的生产级 Spring 应用程序,并使用 Spring Integration 提供与消息代理的连接。
Spring Cloud Stream 还为一些供应商的消息中间件提供了个性化的独立配置实现。还引入了持久化发布 - 订阅,消费者组 和 分区 的概念。
Stream 介绍
简单介绍
Spring Cloud Stream 本质上是整合了 Spring Boot 和 Spring Integration,实现了一套轻量级的消息驱动的微服务框架。通过查看 Spring Cloud Stream 依赖包的继承关系来了解其主要功能,依赖包含了 spring-message、spring-integration-core、spring-integration-jms、spring-retry。
可以应用上添加 @EnableBinding 注解启用绑定来连接到消息代理,在方法上添加 @StreamListener 监听端点接收流处理事件。
Spring Cloud Stream 为 Kafka 和 Rabbit MQ 提供了支持。
2.0 新特性
Spring Cloud Stream 引入了些新特性、增强和更改改。以下概述了主要部分:
- Polling Consumers(轮询消费者):引入轮询的消费者,让应用程序可控制消息处理率。
- Micrometer Support(Micrometer 支持):Metrics 度量切换到 Micrometer 。 MeterRegistry 也作为 bean 提供,以便自定义应用程序可以自动装配它以捕获自定义指标。
- New Actuator Binding Controls(新的绑定控制):新的执行器绑定控件可让您可视化和控制Bindings生命周期。
- Configurable RetryTemplate(可配置的 RetryTemplate):除了提供配置 RetryTemplate 的属性之外,允许提供自己的模板,有效地覆盖框架提供的模板。 要使用它,在应用程序中将其配置为 @Bean。
官方示例
- 接收外部消息
1
2
3
4
5
6
7
8
9
10
11
12
13
public class VoteRecordingSinkApplication {
public static void main(String[] args) {
SpringApplication.run(VoteRecordingSinkApplication.class, args);
}
public void processVote(Vote vote) {
votingService.recordVote(vote);
}
}
@EnableBinding 注解将一个或多个接口作为参数(在本例中,该参数是单个接收器接口)。接口声明输入和输出通道。Spring Cloud Stream 提供源、接收器和处理器接口。还可以自定义接口。
Sink 接口定义
1
2
3
4
5
6public interface Sink {
String INPUT = "input";
SubscribableChannel input();
}@Input 注解定义了一个输出通道,应用程序通过该通道接收消息。
@Output 注解定义了一个输出通道,应用程序通过该通道发送消息。
@Input 和 @Output 注释可以将通道名称作为参数。 如果未提供名称,则使用带注释的方法的名称。
通道使用
Spring Cloud Stream 会创建的通道接口的实现,使用时在应用中注入该接口的 Bean,如下面的测试示例:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
public class StreamApplicationTests {
private Sink sink;
public void contextLoads() {
assertNotNull(this.sink.input());
}
}
Stream 主要概念
Spring Cloud Stream 定义了一些基础概念来对各种不同消息中间件做抽象,简化了消息驱动的微服务应用程序的编写。主要概念如下:
程序模型
Spring Cloud Stream 应用程序通过注入的输入和输出消息通道(Message Channel)与外界通信,通过绑定器(Binder)实现通道与外部消息中间件关联。
下图定义了两条输入通道和三条输出通道来传递消息,而绑定器为这些通道和消息中间件提供桥接。
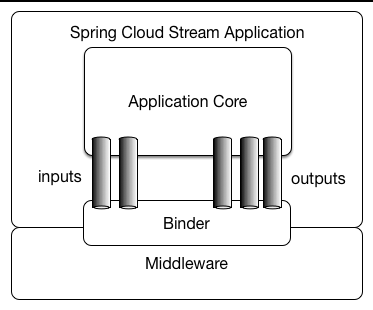
Binder抽象
Binder(绑定器) 是 Spring Cloud Stream 中一个非常重要的概念,它屏蔽了已支持的各种消息中间件之间的细节差异,实现了应用程序与消息中间件的隔离,通过向应用程序暴露统一的 Channel 通道,使用应用程序不需要再考虑不同的消息中间件的实现,当需要升级或更换消息中间件时,只需更换对应的 Binder 而不需要修改任何 Spring Boot 的应用逻辑。
在没有绑定器的况下,Spring Boot 应用与具体的消息中间件交互是强依赖关系,而不同的消息中间件之间存在细节差异,当需要对消息中间件升级或更换时,则要付出非常大的代价来实施。
Spring Cloud Stream 为 Kafka 和 Rabbit MQ 提供默认的 Binder 实现。 Spring Cloud Stream 还提供了一个专门用于测试的 TestSupportBinder,它保留了一个未经修改的通道,以便测试可以直接与通道交互,进行可靠测试断言。若要使用 RabbitMq 和 Kafka 以外的消息中间件,可以使用扩展 API 来自定义 Binder。
Spring Cloud Stream 会自动检测并使用类路径中找到的 Binder。 也可以在相同代码中使用不同消息中间件,但需要时包含与之相对应的 Binder。对于更复杂的场景,也可以在应用程序中打包多个 Binder,并让它在运行时选择 Binder(甚至为不同的通道使用不同的绑定器)。
Spring Cloud Stream 使用 Spring Boot 进行配置,Binder 抽象使 Spring Cloud Stream 应用可以灵活地连接到消息中间件。例如,部署者可以在运行时通过属性配置动态选择通道连接的目标(例如 Kafka 主题或 RabbitMQ 交换)。此配置可以通过外部配置属性以及 Spring Boot 支持的任何形式提供(包括应用程序参数,环境变量和 application.yml 或 application.properties 文件)。
示例:
1 | # 指定输入通道的目标 |
将输入通道绑定到 Kafka 的 raw-sensor-data Kafka 主题,或绑定到 RabbitMQ 的 raw-sensor-data Exchange 中。该属性与 @Input 注解的 value 属性效果等同,如果未设置 destination 属性,则使用 。
注意:如果 @EnableBinding 注解的 value 属性值为 Processor.class ,则会创建 input、output、destination 三个共享主题。输入通道在消费者端绑定,输出通道在生产者端绑定,生产者与消费者分别是两个应用。通常生产者端通道只绑定输出通道,@EnableBinding 注解 value 属性指定为 Source.class;消费者端只绑定输入通道,@EnableBinding 注解 value 属性指定为 Sink.class。
发布-订阅
Spring Cloud Strean 应用程序之间的通信遵循 发布 - 订阅 模型,其中数据通过共享主题( Topic )进行广播。下图显示了一组交互的 Spring Cloud Stream 应用程序的典型部署。
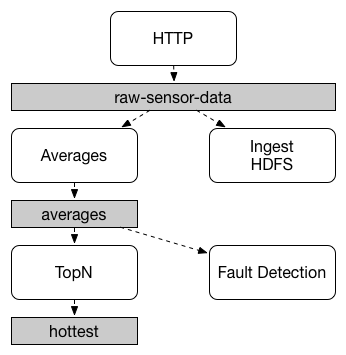
发布 - 订阅 通信模型降低了生产者和消费者的复杂性,并允许在不中断现有流的情况下将新增的应用程序的输入通道绑定到即有的 Topic 中即可实现功能扩展,不需改变原有已实现的任何内容。通过共享主题 而不是点 对点队列 进行通信可以减少微服务之间的耦合。
Spring Cloud Stream 的 topic 是个抽象概念,用来代表发布共享消息给消费者的地方。在不同的消息中间件中对应不同的概念。比如,在 RabbitMq 中,对应 Exchang;而在 Kafka 中则对应 Topic。
消费者组
虽然 发布 - 订阅 模型通过共享主题可以轻松连接应用程序,但通常会为应用部署多个实例来扩展处理能力(高可用和负载均衡),只希望消息被消费一次。
Spring Cloud Stream 提供了 消费者组 概念,使同一应用的多个实例处于竞争的消费者关系中,消息只被其中一个实例处理。
Spring Cloud Stream 通过消费者组的概念对此行为进行建模(Spring Cloud Stream 消费者组概念参考了 Kafka 消费者组,两者类似),每个消费者绑定都可以使用 spring.cloud.stream.bindings.<channelName>.group 属性来指定组的名称。
如以下配置示例,将消费者实例分为了两个组:
1 | # spring.cloud.stream.bindings.<channelName>.group=hdfsWrite |
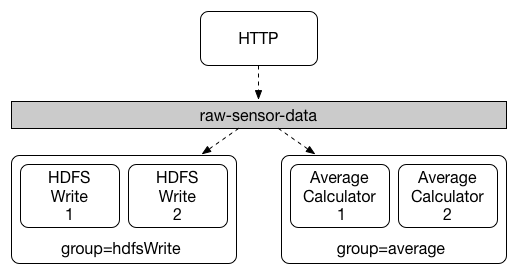
订阅 指定目标的 所有组 都会收到已发布数据的副本,但每个组中只有一个成员处理消息。
默认情况下,当未指定消费组时。Spring Cloud Stream 会为应用程序分配给一个匿名的、独立的单成员消费组,该消费组与所有其他消费组都具有发布-订阅关系。
消费者类型
支持两种类型的消费者:
- 消息驱动(或称为异步)
- 轮询(或称为同步)
在版本 2.0 之前,仅支持异步消费者。消息一旦可用,线程就可以处理消息。如果要控制处理消息的速率,可能需要使用同步消费者。
持续性
与 Spring Cloud Stream 应用固定的 发布 - 订阅 模式一致,消费者组订阅是持续性的。也就是说,绑定器实现确保组订阅是持续性的,一旦为组创建了至少一个订阅,该组就会接收消息,即使在组中的所有应用程序停止时发送消息也是如此。
注意:匿名订阅本质上是非持续的。 对于某些绑定器实现(例如 RabbitMQ ),可能有非持续的组订阅。
通常,在将应用程序绑定到指定目标时,最好始终指定消费者组。 在扩展 Spring Cloud Stream 应用程序时,必须为每个输入绑定指定一个消费者组,这样做可以防止应用程序的实例接收重复的消息(除非需要这种行为,这是不常见的)。
支持分区
Spring Cloud Stream 为应用程序的多个实例之间提供数据分区支持,当生产者将消息数据发送给多个消费者实例时,确保包含某些公共特征的消息始终由同一个消费者实例处理。
在分组场景中,消息是被实例集群中的某一个处理,具体那一个是不可控制的,无法满足某些需要指定实例处理消息的场景,比如监控服务,需要获取指定实例的数据,就需要让指定的实例来处理消息。
分区就能解决分组场景中无法指定具体实例的问题,生产者为消息增加一个固有的特征ID来进行分区,消费者配置分区,使得这些 ID消息被发送到指定的实例。
Spring Cloud Stream 为分区提供了通用的抽象,以统一的方式实现分区处理(在消息中间件上层实现)。因此,无论代消息中间件是否支持分区( Kafka 支持,RabbitMq 不支持),都可以使用分区。
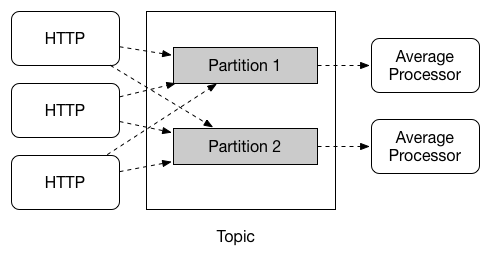
注意: 要设置分区处理方案,必须同时配置数据生产端和数据消费端。
Binder 绑定器详解
Spring Cloud Stream 提代了一个 Binder 抽象,用于连接外部中间件的目标(共享主题)。这章节了解 Binder SPI 背后的主要概念,其主要组件以及特定于实现的详细信息。
生产者与消费者
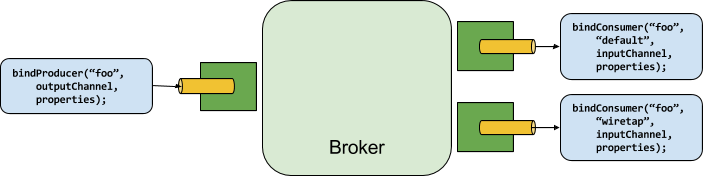
Binder SPI
Binder SPI 由许多接口,开箱即用的工具类和发现策略组成,这些策略提供了可连接外部消息中间件的可插拔机制。
SPI 的关键点是 Binder 接口,这是一种将输入和输出连接到外部中间件的策略。 以下显示了 Binder 的定义:
1 | public interface Binder<T, C extends ConsumerProperties, P extends ProducerProperties> { |
应用程序通过该接口来实现生产者与输出通道绑定,消费者与输入通道绑定。
- 绑定生产者:调用 bindProducer() 方法时,第一个参数是消息中间件的目标名称(共享主题),第二个参数是发送消息的本地通道实例,第三个参数是为该通道创建适配器使用的属性(如分区键表达式)。
- 绑定消费者: bindConsumer() 方法时,第一个参数是目标名称,第二个参数提供逻辑消费者组的名称。 如果绑定相同组名的消费者实例存在多个,则消息在这些消费者实例之间进行负载均衡,以便每条消息仅由每个组中的单个消费者实例处理(即,它遵循正常排队语义)。
一个典型的绑定器实现包括以下内容:
- 一个实现绑定器接口的类。
- 一个 Spring @Configuration 类,用业创建 Binder 类型的 Bean及连接消息中间件基础结构。
- 在类路径下存在一个 META-INF/ spring.binders 文件,包含一个或多个绑定器定义的类。如下示例:
1
2kafka:\
org.springframework.cloud.stream.binder.kafka.config.KafkaBinderConfiguration
绑定器检测
Spring Cloud Stream 依赖于 Binder SPI 的实现来执行将通道连接到消息代理的任务。 每个 Binder 实现通常连接到一种类型的消息传递系统。
默认情况下,Spring Cloud Stream 依靠 Spring Boot 的自动配置来配置绑定过程。 如果在类路径上找到单个 Binder 实现,则Spring Cloud Stream 会自动配置它。
例如,需要绑定到 RabbitMQ 的 Spring Cloud Stream 应用需要添加以下依赖:
1 | <!-- RabbitMQ --> |
多个绑定器
当类路径上存在多个 绑定器 时,应用程序必须指示每个通道绑定使用哪个绑定器。 每个绑定器配置都包含一个 META-INF /spring.binders 文件,该文件是一个简单的属性文件,如以下示例所示:
1 | rabbit:\ |
对于其他提供的 绑定器 实现(如 Kafka),也存在类似的文件,如果是自定义绑定器实现也需要提供这个文件。键表示绑定器实现的标识名(绑定器类型),而该值是配置类的逗号分隔列表,每个配置类都包含一个且只有一个类型为org.springframework.cloud.stream.binder.binder 的 bean 定义。
可以使用 spring.cloud.stream.defaultBinder 属性指定默认的绑定器实现,也可以通过在每个通道绑定上配置绑定器来单独执行。
例如,指定 默认绑定器为 rabbit
1 | =rabbit |
例如,从 kafka 读取并写入 rabbitmq 的处理器应用程序(具有分别为读和写命名的输入和输出通道)可以指定以下配置:
1 | =kafka |
多绑定器配置
若在类路径下找个多个绑定器实现,Spring Cloud Stream 在为消息通道做绑定时,无法判断选择那个具体的绑定器,就需要手动为每个输出输出通道指定具体的绑定器。
默认情况下,绑定器共享应用程序的 SpringBoot 自动配置,以便为在类路径上找到的每个绑定器的创建一个实例。
如果应用连接到同一类型的多个绑定器,则可以为每个绑定器配置不同的环境参数。
如下示例,显示连接到两个 RabbitMQ 实例的典型配置。
1 | =thing1 |
注意:如果采用显式方式配置绑定器,则会禁用默认绑定器的配置。这样的话,所有的绑定器都必须包含在配置中。
绑定可视化和控制
从版本2.0开始,Spring Cloud Stream 通过 Actuator 端点支持 Bindings 的可视化和控制。
添加依赖:
pom.xml
1
2
3
4
5
6
7
8
9
10
11
12
13
14<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<!-- WebFlux 框架依赖
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-webflux</artifactId>
</dependency>
-->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-actuator</artifactId>
</dependency>配置暴露 bindings 端点
1
=bindings
如果以上满足,应用启动时可以看到如下打印:
1
2
3: Mapped "{[/actuator/bindings/{name}],methods=[POST]. . .
: Mapped "{[/actuator/bindings],methods=[GET]. . .
: Mapped "{[/actuator/bindings/{name}],methods=[GET]. . .可视化连接
1
2
3
4
5# 当前所有 bindings 的 url
http://<host>:<port>/actuator/bindings
# 单个绑定
http://<host>:<port>/actuator/bindings/myBindingName还可以通过带 JSON 格式的状态参数访问 URL 来停止、启动、暂停和恢复单个绑定,如下示例:
1
2
3
4
5
6
7curl -d '{"state":"STOPPED"}' -H "Content-Type: application/json" -X POST http://<host>:<port>/actuator/bindings/myBindingName
curl -d '{"state":"STARTED"}' -H "Content-Type: application/json" -X POST http://<host>:<port>/actuator/bindings/myBindingName
curl -d '{"state":"PAUSED"}' -H "Content-Type: application/json" -X POST http://<host>:<port>/actuator/bindings/myBindingName
curl -d '{"state":"RESUMED"}' -H "Content-Type: application/json" -X POST http://<host>:<port>/actuator/bindings/myBindingName注意: PAUSED 和 RESUMED 需要绑定器提供支持。目前只有 Kafka 绑定器支持 PAUSED 和 RESUMED 状态。
绑定器和绑定通道配置
绑定器属性
绑定器属性配置类:org.springframework.cloud.stream.config.BinderProperties 。
自定义绑定器配置时,可以使用以下属性,但必须以 spring.cloud.stream.binders.<configurationName> 为前缀,其中 configurationName 为绑定器名,即 spring.cloud.stream.bindings.<channelName>.binder的值。
- type:绑定器类型。通常是从类路径下的 META-INF/spring.binders 文件中指向绑定器的键。默认与配置的名相同。
- inheritEnvironment:配置是否继承了应用程序本身的环境。默认为 true。
- environment:自定义绑定器的环境属性。默认为 empty。
- defaultCandidate:绑定器配置是否可以被视为默认绑定器,或者只能在显式引用时使用。默认为 true。若想不影响默认配置时,可以将属性设置为 false。
绑定服务属性
属性类:org.springframework.cloud.stream.config.BindingServiceProperties
属性前缀:spring.cloud.stream.*
绑定通道属性
属性类:org.springframework.cloud.stream.config.BindingProperties
绑定属性支持使用这种格式
1
=<value>
channelName 表示要配置的通道名(如,为 Source 设置为 output)。
为避免冲突,Spring Cloud Stream 支持使用如下配置为所有通道设置属性
1
=<value>
在避免扩展属性重复时,使用这种格式配置:
1
=<value>
通用绑定通道属性
属性类:org.springframework.cloud.stream.config.BindingProperties
属性前缀:spring.cloud.stream.bindings.<channelName>.
通道绑定通道属性对输入绑定和输出绑定都有效。示例:spring.cloud.stream.bindings.input.destination=ticktock,默认值可使用 spring.cloud.stream.default 前缀来定义(如,spring.cloud.stream.default.contentType=application/json)
- destination:绑定消息中间件通道的目标(例如,RabbitMQ 的 Exchange 或 Kafka 的 Topic)。如果通道是个消费者绑定,则可以绑定多个目标,多个目标名称是以逗号分隔的字符串(String[])。如果没有设置,默认通道名作为目标名,此默认值不可覆盖。
- group:默认值 null,通道上的消费者组,仅用于输入绑定。
- contentType:默认值 application/json,通道的内容类型。
- binder:默认 null, 通道绑定使用的绑定器。如果存在默认绑定器,则使用。
消费者属性
属性类:org.springframework.cloud.stream.binder.ConsumerProperties
属性前缀:spring.cloud.stream.bindings.<channelName>.consumer.,例如:spring.cloud.stream.bindings.input.consumer.concurrency=3
可以使用前缀 spring.cloud.stream.default.consumer.* 设置默认值,例如:spring.cloud.stream.default.consumer.headerMode=none
生产者属性
属性类:org.springframework.cloud.stream.binder.ProducerProperties
属性前缀:spring.cloud.stream.bindings.<channelName>.producer.,例如:spring.cloud.stream.bindings.input.producer.partitionKeyExpression=payload.id
可以使用前缀 spring.cloud.stream.default.producer.* 设置默认值,例如:spring.cloud.stream.default.producer.partitionKeyExpression=payload.id
动态绑定目标
除了使用 @EnableBinding 定义的通道外,Spring Cloud Stream还允许应用程序将消息发送到动态绑定的目标,为很有用。例如,当需要在运行时确定目标,应用程序可以使用由 @EnableBinding 注解自动注册的BinderAwareChannelResolver bean 来实现。
spring.cloud.stream.dynamicDestinations 属性可用于将动态目标名称限制为已知集(白名单), 如果未设置此属性,则可以动态绑定任何目标。
BinderAwareChannelResolver 可以直接使用,如以下 REST 控制器示例所示,使用路径变量来决定目标通道:
1 |
|
执行如下请求,分析绑定动态目标
1 | curl -H "Content-Type: application/json" -X POST -d "customer-1" http://localhost:8080/customers |
在消息中间件会创建名为 customers 和 orders 两个主题(目标)(RabbitMQ 的 Exchange,或 Kafka 的 Topic),数据发布到合适的目标。
BinderWareChannelResolver 是一个通用的 Spring Integration DestinationResolver,可以注入其他组件中,例如,在使用基于传入 JSON 消息的目标字段的 SPEL 表达式的路由器中。以下示例包括一个读取 SPEL 表达式的路由器:
1 |
|
路由接收器应用使用此技术按需创建目标。
如果事先事知道通道名称,则可以将生产者属性配置为与任何其它目标一样。或者,注册 NewBindingCallback<>bean,则会在创建绑定之前回调它,回调采用绑定器使用的扩展生产者属性的泛型类型。回调用一方法:
1 | void configure(String channelName, MessageChannel channel, ProducerProperties producerProperties, |
以下示例如何使用 RabbitMQ 绑定器
1 |
|
备注:如果需要支持具有多个绑定器类型的动态目标,使用 Object 作为泛型,并根据需要强制 extended 参数。
连接多应用实例
虽然 Spring Cloud Stream 使单个 Spring Boot 应用程序可以轻松连接到消息中间件,但 Spring Cloud Stream 的典型场景是创建多应用管道,用于微服务应用程序相互发送数据。 可以把需要相互通信的应用的输入输出通道绑定到相同的目标上。
假设设计要求 Time Source 应用程序将数据发送到 Log Sink 应用程序。 可以将两个应用与公共目标 ticktock 绑定。
1 | # Time Source 应用输出通道目标 |
实例索引与计数
在扩展 Spring Cloud Stream 应用程序时,每个实例都可以接收同一应用存在的实例数以及自己的实例索引信息。
Spring Cloud Stream 通过 spring.cloud.stream.instanceCount 和 spring.cloud.stream.instanceIndex 属性执行此操作。
例如,如果有三个 HDFS 接收器应用程序实例,则所有三个实例都将 spring.cloud.stream.instanceCount 设置为 3,并且各个实例将 spring.cloud.stream.instanceIndex 分别设置为 0,1 和 2。
通过 Spring Cloud Data Flow 部署 Spring Cloud Stream 应用程序时,会自动配置这些属性。当 Spring Cloud Stream 应用程序独立启动时,必须正确设置这些属性。默认情况下,spring.cloud.stream.instanceCount 为1,spring.cloud.stream.instanceIndex 为 0。
在多实例的方案中(实例集群),正确配置这两个属性对于解决分区行为非常重要,并且某些绑定程序(例如,Kafka 绑定器)始终需要这两个属性,以确保数据在多个消费者实例中正确分离。
分区配置
Spring Cloud Stream 分区必须在输出通道和输入通道都进行配置。
为分区配置输出绑定
通过设置 partitionkeyExpression 或 partitionkeyExtractor 属性以及其 partitionCount 属性来配置输出绑定以发送分区数据。如下示例:
1
2=payload.id
=5上面示例配置,使用以下逻辑将数据发送到目标分区。
根据 partitionKeyExpression 计算发送到分区输出通道的每条消息的分区键值。partitionKeyExpression 是个 SpEL 表达式,根据输出的消息计算该表达式以取出分区键。
如果 SpEL 表达式不足以满足需求,可以通过提供 org.springframework.cloud.stream.binder.PartitionKeyExtractorStrategy 的实现并将其配置为 Bean 来计算分区键值。
如果在应用程序上下文中有多个类型为 org.springframework.cloud.stream.binder.PartitionKeyExtractorStrategy 的Bean,则可以通过使用 partitionKeyExtractorName 属性指定其名称来进一步过滤它,如以下示例所示:
1
2
3
4
5//CustomPartitionKeyExtractorClass 实现了 PartitionKeyExtractorStrategy
public CustomPartitionKeyExtractorClass customPartitionKeyExtractor() {
return new CustomPartitionKeyExtractorClass();
}1
2=customPartitionKeyExtractor
=5计算完消息键后,分区选择将目标分区确定为介于 0 和 partitionCount - 1 之间的值。适用于大多数场景的默认计算公司:key.hashCode() % partitionCount ,这还可以在绑定上自定义,可以通过设置要根据 Key(通过 partitionKeyExpression ) 属性计算 SpEL 表达式,也可以通过将 org.springframework.cloud.stream.binder.PartitionSelectorStrategy 的实现配置为 Bean,与 PartitionKeyExtractor 策略类似,当应用程序上下文中有多个此类 Bean 可用时,可以使用spring.cloud.stream.bindings.output.producer.PartitionSelectorName 属性进一步筛选它,如下例所示:
1
2
3
4
public CustomPartitionSelectorClass customPartitionSelector() {
return new CustomPartitionSelectorClass();
}1
=customPartitionSelector
注意:
- 在 2.0 版本之前,PartitionKeyExtractorStrategy 的实现是通过 spring.cloud.stream.bindings.output.producer.partitionKeyExtractorClass 属性设置的。2.0 版本开始后,该属性已过时了,在后续版本可能会移除,改为使用 partitionKeyExtractorName 属性。
- 在 2.0 版本之前,PartitionSelectorStrategy 的实现是通过 spring.cloud.stream.bindings.output.producer.partitionSelectorClass 属性设置的。2.0 版本开始后,该属性已过时了,在后续版本可能会移除,改为使用 partitionSelectorName 属性。
为分区配置输入绑定
通过设置分区属性及应用本身的 **instanceIndex ** 和 **instanceCount ** 属性,将输入绑定( 使用通道名输入 ) 配置为接收分区数据,如下示例:
1
2
3spring.cloud.stream.bindings.input.consumer.partitioned=true
spring.cloud.stream.instanceIndex=3
spring.cloud.stream.instanceCount=5InstanceCount 值表示应用程序实例的总数,应在这些实例之间对数据进行分区。
InstanceIndex 值表示当前实例的索引,必须是多个实例之间的唯一值,其值介于 0 和 InstanceCount-1 之间。实例索引帮助每个实例识别来自接收数据的唯一分区。若绑定器自身不支持区分技术,则需要 Spring Cloud Stream 的分区支持:
例如,对于 RabbitMQ,每个分区都有一个队列,队列名称包含实例索引。对于 Kafka,如果 autoRebalanceEnabled 为 true(默认值),则实例分布分区由 Kafka 自身负责,而不需要这些属性;如果autorebalanceEnabled 设置为 false,绑定器将使用 instanceCount 和 instanceIndex 来确定实例订阅的分区(必须至少具有与实例一样多的分区),此时,是由绑定器分配分区而不是 Kafka。如果特定分区的消息总是转到同一个实例,这可能很有用。
当绑定器配置需要这两个属性时,必须正确设置这两个值,以确保只有一个实例消费所有数据。
虽然使用多个实例进行分区数据处理的场景在设置起来可能很复杂(指在运行时为各个实例设置这两个参数,因为不能在配置文件中设置成固定值),Spring Cloud Dataflow 可以通过正确填充输入和输出值以及依赖运行时基础设施来提供有关实例索引和实例计数的信息,从而显著简化流程。
Spring Cloud(十六):消息驱动-Stream 概念、绑定器、属性
http://blog.gxitsky.com/2019/05/09/SpringCloud-16-stream-binder-property-concept/