Sharding-JDBC系列(一):Sharding-JDBC介绍、功能、内部结构概览
Sharding-JDBC 已经是一款非常流行、轻量级、易用的客户端侧的数据库中间件。更多认识 Sarding-JDBC 可参考 深度认识 Sharding-JDBC:做最轻量级的数据库中间层 。
Sharding-JDBC 最初是当当自研的数据库中间件,后在开源社区推广流行,后被推荐到 Apache 孵化更名为 Apache ShardingSphere。
此系列文章都是基于 Sharding-JDBC 4.x版本, 在写此文章时,正式发布的是 4.1.0版本,点此 4.x 官方文档。
当业务快速发展,数据库中的表越来越多,表中的数据越来越多,当一张表的数据达到几千万时,对数据的操作会越来越慢,查询耗时会较长,如果存在多表联合查询的话,甚至卡死拖垮系统。
要解决数据库单表大数据量带来的压力,就要考虑分表方案,通用采用水平分表;要解决单台服务器资源有限,难以支撑大数据高并发问题,就要考虑分库,通常是按业务分库,并分布式部署。
分表分库方案基本有两种,一种是采用代理中间件的方式,在客户端与数据库中间增加了中间代理层,如 MyCat;另一种是在客户端侧分表分库,未使用中间层,与应用集成在一起,无须额外部署,如 Sarding-JDBC。
ShardingSphere
简介
Apache ShardingSphere 是一套开源的分布式数据库中间件解决方案组成的生态圈,它由 JDBC、Proxy 和 Sidecar这 3 款相互独立,却又能够混合部署配合使用的产品组成。
ShardingSphere 中的 JDBC 指的就是 Sharding-JDBC,ShardingSphere已经在2020年4月16日从Apache孵化器毕业,成为Apache顶级项目。
Apache ShardingSphere 定位为关系型数据库中间件,旨在充分合理地在分布式的场景下利用关系型数据库的计算和存储能力,而并非实现一个全新的关系型数据库。
详细可参考官方文档:Apache ShardingSphere ,ShardingSphere-Overview 4.x,Github-Shardingsphere。
Apache ShardingSphere 三大产品均提供标准化的数据分片、分布式事务和数据库治理功能,可适用于如 Java 同构、异构语言、云原生等各种多样化的应用场景。
功能列表
数据分片
数据分片功能主要由 ShardingSphere-JDBC 提供:
- 分库 & 分表
- 读写分离
- 分片策略定制化
- 无中心化分布式主键
分布式事务
- 标准化事务接口
- XA 强一致性事务
- 柔性事务
数据库治理
- 配置动态化
- 编排 & 治理
- 数据脱敏
- 可视化链路追踪
- 弹性伸缩(规划中)
Sharding-JDBC
介绍
Sharding-JDBC 是一款轻量 Java 框架,采用无中心化架构,在 Java JDBC 层提供增强服务。 客户端直接连接到数据库,它以 jar 的形式提供服务,不需要额外的部署和依赖。 它可以被视为增强的 JDBC 驱动程序,它与 JDBC 和各种 ORM 框架完全兼容。
详细可参考官方文档:Sharding-JDBC 4.x 快速入门,Sharding-JDBC 4.x 使用手册 ,SharingShpere-example 使用示例。
- 适用于任何基于 Java 的 ORM 框架,如 JPA,Hibernate,Mybatis,Spring JDBC Template 或直接使用 JDBC。
- 基于任何第三方数据库连接池,如 DBCP,C3P0,BoneCP,Druid,HikariCP。
- 支持任何符合JDBC标准的数据库:MySQL,Oracle,SQLServer 和 PostgreSQL 。
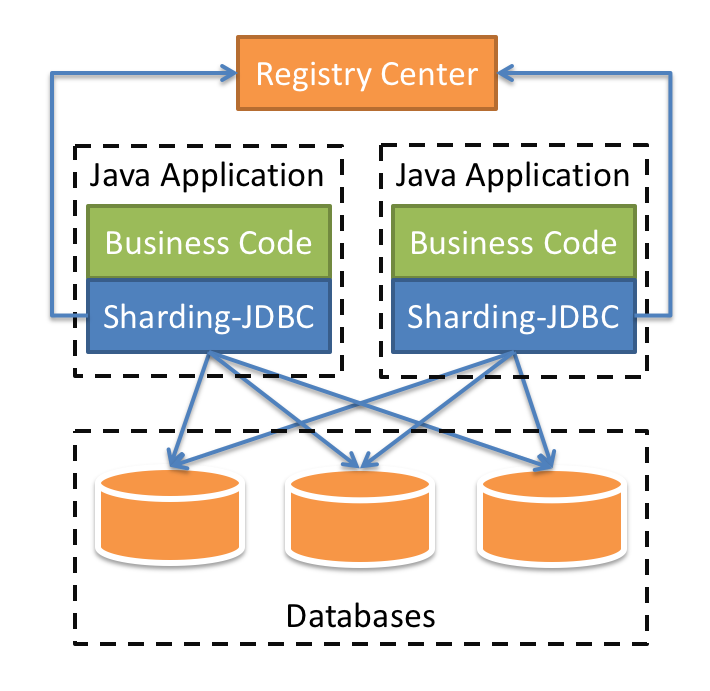
内部结构
下图包含了数据分片和读写分离的内部实现结构。
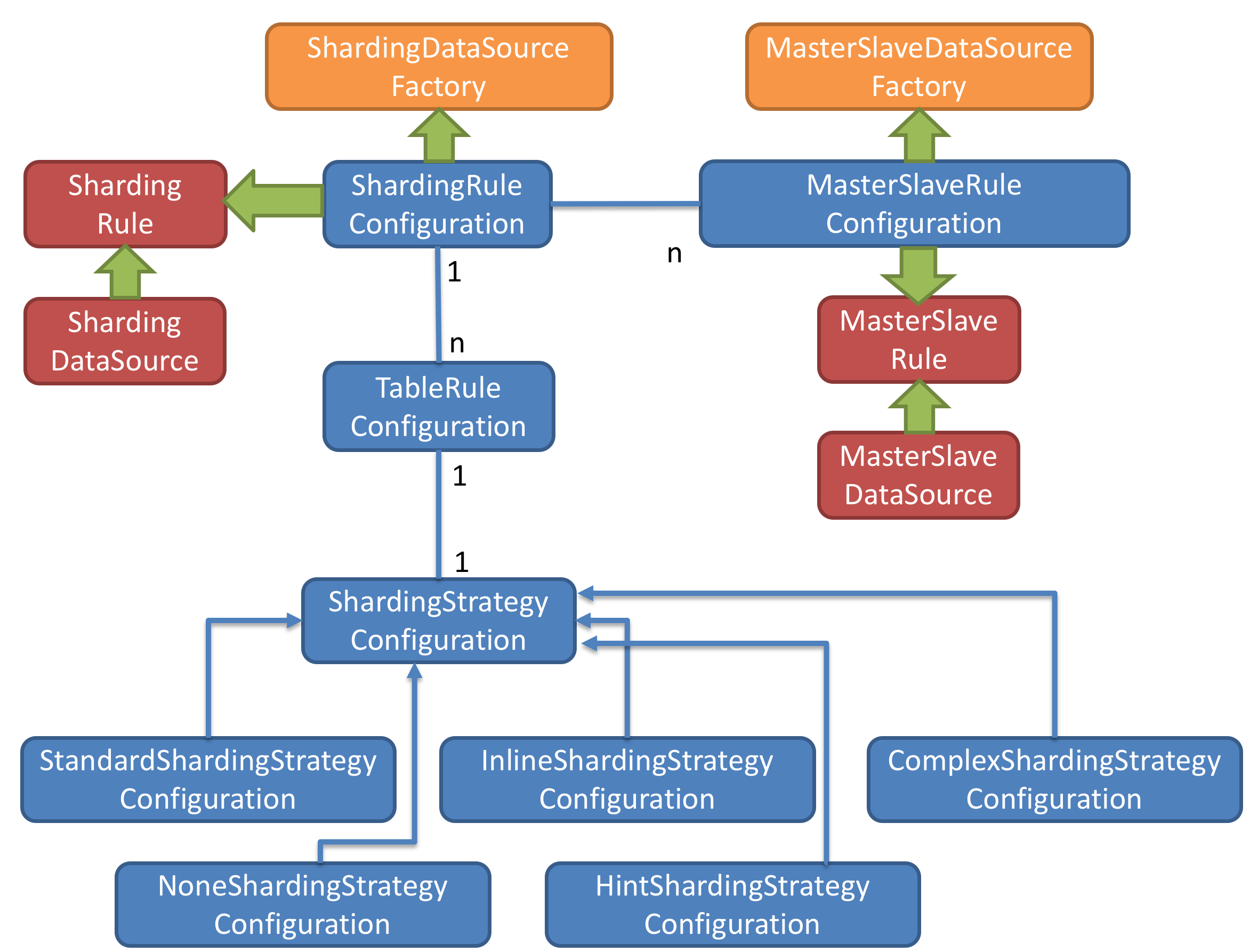
数据源
黄色部分:黄色部分表示的是 Sharding-JDBC 的入口 API,采用工厂方法的形式提供。
目前有 ShardingDataSourceFactory 和 MasterSlaveDataSourceFactory 两个工厂类。
- ShardingDataSourceFactory:用于创建 分库分表 或 分库分表 + 读写分离 的JDBC驱动。
- MasterSlaveDataSourceFactory:用于创建独立使用读写分离的 JDBC 驱动。
配置对象
蓝色部分:图中蓝色部分表示的是 Sharding-JDBC 的配置对象,提供灵活多变的配置方式。
ShardingRuleConfiguration 是分库分表配置的核心和入口,它可以包含多个 TableRuleConfiguration 和MasterSlaveRuleConfiguration。
每一组相同规则分片的表配置一个 TableRuleConfiguration。如果需要分库分表和读写分离共同使用,每一个读写分离的逻辑库配置一个 MasterSlaveRuleConfiguration。
每个 TableRuleConfiguration 对应一个ShardingStrategyConfiguration,它有 5 种实现类可供选择。
仅读写分离使用 MasterSlaveRuleConfiguration 即可。
内部对象
红色部分:图中红色部分表示的是内部对象,由 Sharding-JDBC 内部使用,应用开发者无需关注。
Sharding-JDBC 通过 ShardingRuleConfiguration 和 MasterSlaveRuleConfiguration 生成真正供 ShardingDataSource 和 MasterSlaveDataSource 使用的规则对象。
ShardingDataSource 和 MasterSlaveDataSource 实现了 DataSource 接口,是JDBC的完整实现方案。
初始化流程
- 配置 Configuration 对象。
- 通过 Factory 对象将 Configuration 对象转化为 Rule 对象。
- 通过 Factory 对象将 Rule 对象与 DataSource 对象装配。
- Sharding-JDBC 使用 DataSource 对象进行分库。
使用约定备注:在 org.apache.shardingsphere.api 和 org.apache.shardingsphere.shardingjdbc.api 包中的类是面向用户的 API,每次修改都会在 release notes 中明确声明。 其他包中的类属于内部实现,可能随时进行调整,请勿直接使用。
快速入门
引入Maven依赖
1 | <dependency> |
Spring Boot 开发可以引入 starter 包:
1 | <dependency> |
注意:请将 ${latest.release.version} 更改为实际的版本号,目前最新版本的是 4.1.0 。
规则配置
ShardingSphere-JDBC 可以通过 Java,YAML,Spring 命名空间和 Spring Boot Starter 这 4 种方式进行配置,开发者可根据场景选择适合的配置方式。 详情请参见配置手册。
创建数据源
通过 ShardingSphereDataSourceFactory 工厂和规则配置对象获取 ShardingSphereDataSource。
该对象实现自 JDBC 的标准 DataSource 接口,可用于原生 JDBC 开发,或使用 JPA, MyBatis 等 ORM 类库。
1 | DataSource dataSource = ShardingSphereDataSourceFactory.createDataSource(dataSourceMap, configurations, properties); |
Sharding-JDBC系列(一):Sharding-JDBC介绍、功能、内部结构概览
http://blog.gxitsky.com/2019/09/19/sharding-jdbc-1-overview/