MQ系列(二):ActiveMQ集群,独占消费者,消息组,消息顺序性
ActiveMQ 同样支持集群部署,支持客户端集群和服务端集群,实现可靠的高性能负载均衡。
ActiveMQ 提供了独占消费者配置,可保证消息消费的顺序性,消息组是对独占消费者功能的增强。
ActiveMQ集群
ActiveMQ 集群概念和设置参考官方文档:ActiveMQ Features > Clustering。
队列消费者集群
竞争消费者模式
ActiveMQ 支持多个消费者监听同一个消息队列,实现可靠的高性能负载均衡。在企业集成中,这种情况称为 竞争消费者 模式,如下图。
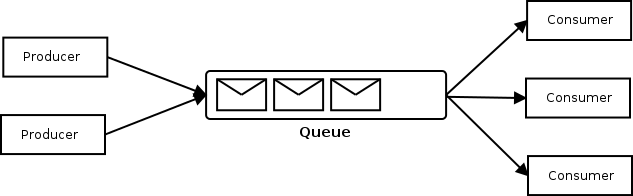
在集群环境中,一个消费者应用服务会部署多个实例,自然就形成了 竞争消费者模式,消息代理服务接收消息,将其排队并分发给所有消费者。这样有些好处:
- 消费者实例可动态的注册到队列中,无需修改队列中任何配置,与其它竞争的消费者一样工作。
- 与使用负载均衡器相比,可用性更高。负载均衡器通常依赖监视系统来找出哪些服务实际不可用。而竞争消费者模式中,失败的消费者就不会收到消息,因此即使没有监控,消息也不会传递给它。
- 高可靠性。如果消费者失败,则任何未确认的消息都会重新发送到队列中的其他消费者。
不利的一面是,竞争消费者模式不能满足需要按顺序处理消息(确保消息的顺序性)的系统需求。要实现此问题,应将竞争消费者模式与 其它ActiveMQ 特性(如 独占消费者 和 消息组)结合使用。
竞争消费者模式 中的多个消费者,都是为了从单个点对点通道接收消息而创建。当通道传递消息时,任何消费者都可能收到该消息,消息代理服务确定哪个消费者实际接收了该消息,实际上消费者之间相互竞争以成为接收者。此方案仅适用于点对点通信;发布/订阅上的多个使用者仅创建每个消息的更多副本。
独占消费者
背景:消息处理无法保证顺序
点队点的队列(Queue)维护了消息的顺序(FIFO),并按顺序将消息分发给不同的消费者,但在多个消费者实例情况下,无法保证按顺序处理消息,因为消息将在不同的线程中同时处理。
有时,保证消息处理的顺序非常重要。例如,在订单插入完成之前,不能处理订单的更新;或者在时间上回退,用旧的订单覆盖新的订单的更新。
因此,在 J2EE集群中,通常是指定一个监听消费者,以便在队列中只有一个消费者,以避免顺序失效。但存在的问题是,如果这个指定的消费者崩溃,就没有可处理队列中消息的消费者了。
独占消费者:确保获取消息的顺序
ActiveMQ 从 4.x 开始多了一个新特性,称为独占消费者或独占队列,它避免了最终消费者必须锁定任何内容(队列)。
代理将选择一个 消息消费者 来获取队列的所有消息,以确保排序。如果该使用者失败,代理将自动故障转移并选择另一个使用者。
这对于构建集群化,高可用性的分布式服务是非常有用。
创建独占消费者示例
consumer.exclusive默认为false,在创建队列时,指定为true表示为独占队列。1
2queue = new ActiveMQQueue("TEST.QUEUE?consumer.exclusive=true");
consumer = session.createConsumer(queue);备注:更多消费者配置项可参考 Destination Options。
消息组
消息组 是对 独占消费者 功能的增强,具有以下功能:
- 确保在单个队列中处理相关消息的顺序。
- 支持一个队列多个消费者的消息处理负载均衡。
- 如果某个消费者出现故障,则将高可用性 / 自动故障转移到其他消费者。
所以在逻辑上,消息组就像是一个并行的独占消费者。不是将所有消息发送给单个使用者,而是使用标准 JMS 头 JMSXGroupID 来定义消息所属的消息组。消息组功能可确保同一消息组的所有消息发送到同一个 JMS 消费者(该消费者保持活动状态)。一旦消费者死亡,则会选择另一个。
另一种对消息组的解释是,消息组跨多个消费者为消息提供的粘性负载均衡;其中 JMSXGroupID 类似于 HTTP Session ID或 cookie 值,而消息代理则像 HTTP 负载均衡器。JMSXGroupID 可以是任意字符串,通常会结合业务,日期等组合而成。
消息组如何工作
当消息被分发给消费者时,将检查 JMSXGroupID。如果存在,则 Broker(代理) 检查用户是否拥有该消息组。由于可能存在大量的消息组,因此会用哈希槽(Hash Buckets),而不是实际的 JMSXGroupID 字符串。
如果没有消费者与消息组关联,则会选择任意一个消费者。JMS 消息消费者将接收具有相同 JMSXGroupID 值的所有其他消息,直到:
- 消费者关闭(或创建消费者的客户端死亡等)。
- 有人通过发送
JMSXGroupSeq值为负数的消息来关闭消息组。
注意:与消息选择器匹配一样,基于 JMSXGroupID 的分组会在将内存中的消息分发之前执行。使用默认的 maxPageSize 选项,如果发往一个组的大量消息出现积压(不能全部放入内存),则可能会阻塞接收其他组的消息。可以修改 maxPageSize 默认值,如下:
1 | <destinationPolicy> |
使用消息组
只需要更改的JMS生产者,设置消息属性,Key 是 JMSXGroupID,值是字符串。如下示例:
1 | Mesasge message = session.createTextMessage("<foo>hey</foo>"); |
关闭消息组
消息组通常是不需要关闭的,只需继承使用它。如果确实要关闭消息组,则可以设置 JMSXGroupSeq 属性值为负数。如下:
1 | Mesasge message = session.createTextMessage("<foo>hey</foo>"); |
上面示例将关闭消息组。如果以后再发送具有相同消息组ID的其它消息,则会将其重新分配给新的消费者。
消息组意义
消息组意味着可以通过可靠性,自动故障转移,负载均衡在整个消费者群集中进行消息的网格处理,也可以按顺序处理消息。
因此,两全其美。 不过,使用上述示例,消息组实际上所做的是使用 用户可定义的分区策略(JMSXGroupID值)在消费者之间划分工作负载。
消息组对开发人员来说,让集群客户端看起来像一个简单的消费者世界,开发者专注于处理消息并完成工作;由代理完成所有复杂的工作。
- 流量分离。
- 跨消费者的消息组负载均衡
- 随着消费者的加入或退出,消费组自动故障迁移会切换到不同的消费者。
总之,如果消息消费需按顺序处理或每条消息的缓存和同步非常重要,那么建议使用消息组来划分流量。
消息组的所有权变更
ActiveMQ 支持名为 JMSXGroupFirstForConsumer 的 boolean 值消息头。 在发送给指定消息组的消费者的第一条消息上设置此消息头。
如果 JMS 连接正在执行故障迁移,同时发生临时网络错误,导致连接从代理(Broker)断开并在稍后重新连接,则将在JMS客户端的掩护下创建一个新的消费者实例(消息组的所有权发生了变更),从而可能会为同一消息组设置另一条具有此头的消息。
此时,可以获取消息组的所有权变更通知,即名为 JMSXGroupFirstForConsumer boolean 值的消息头。如下:
1 | String groupId = message.getStringProperty("JMSXGroupId"); |
在遇到网络错误时刷新缓存以确保状态一致。
添加新的消费者
如果代理(Broker)中已有消息并在之后添加了新的消费者,则最好延迟消息分发,直到所有消费者都出现(或至少给他们足够的订阅时间)。
如果不这样做,则第一个使用者可能会获取所有消息组,并且所有消息都将发送到该消息组。可以通过使用 consumersBeforeDispatchStarts 和 timeBeforeDispatchStarts 目标策略来实现,这两个属性值在 /activemq-5.15.9/conf/activemq.xml中的 <destinationPolicy>标签里设置。
当 consumersBeforeDispatchStarts 和 timeBeforeDispatchStarts 设置的值大于零时,则在消费者数量达到要求或 timeBeforeDispatchStarts 超过延迟时间时立即分发消息。
如果只设置了 consumersBeforeDispatchStarts ,那么消费者连接的超时时间为 1 秒。如果所有消费者断开连接,则消息延迟分发将在下一个消费者连接后再次启用。
下面是延迟 200 ms 发送消息的目标策略:
1 | <destinationPolicy> |
下面是等待存在两个消费者(或两秒)后开始分发消息:
1 | <destinationPolicy> |
如上所有,在分发消息之前设置一个最小的消费者数量或增加一个小延迟时间,可以确保消息分配均衡。
性能竞争需求
内存消耗,负载均衡,复杂性等竞争需求。
默认缓存消息组的行为名为 CachedMessageGroupMap ,被限制为 1024 个消息组,使用的是 LRU(最近最少使用) 缓存策略,可能与期望的消息顺序不符。
CachedMessageGroupMap 使用的内存是有限的,默认仅跟踪最多1024个(或最大配置的大小)组,然后丢失比最新的 1024 个更旧的组的跟踪。这样,如果组数超过了最大值,则最旧的组将失去顺序。
通常用户会关闭组,以便内存中的组的数量维持在配置的限制之下,关于此有相关的讨论 AMQ-6851。
为了防止此限制,可以使用 MessageGroupHashBucket 或 SimpleMessageGroupMap。他们通过将每个组与一个消费者相关联来工作。
SimpleMessageGroupMap会跟踪每个组,但会受到内存耗尽的限制。下面示例了如何启用它:
1
2
3
4
5
6
7
8
9
10
11<destinationPolicy>
<policyMap>
<policyEntries>
<policyEntry queue=">">
<messageGroupMapFactory>
<simpleMessageGroupMapFactory/>
</messageGroupMapFactory>
</policyEntry>
</policyEntries>
</policyMap>
</destinationPolicy>MessageGroupHashBucked会跟踪每个组,并有限制的内存使用。下面示例了如何启用它:
1
2
3
4
5
6
7
8
9
10
11<destinationPolicy>
<policyMap>
<policyEntries>
<policyEntry queue=">">
<messageGroupMapFactory>
<messageGroupHashBucked cachedSize=1024 />
</messageGroupMapFactory>
</policyEntry>
</policyEntries>
</policyMap>
</destinationPolicy>
代理服务集群
在 JMS 上下文中,最常见的集群模式是有一个 JMS代理集合(多个 broker),JMS 客户端将连接到其中一个代理服务,如果该代理关闭,则自动重新连接到其它代理服务。
ActiveMQ 通过在客户端使用 failover:// 协议来实现这一点。如何配置故障转换协议参见 Failover Transport Reference。
如果仅在网络上运行多个代理服务,然后使用静态发现或动态发现将它们告知客户端,则客户端可以轻松地从一个代理故障转移到另一个代理。
然而,此模式下的代理服务之间并不会通信的,相当于独立的代理服务,也就不知道其他代理上的消费者;因此,如果某个代理服务上没有消费者,消息可能会堆积起来而不被消费。
ActiveMQ 有一个出色的功能,需要在客户端侧解决此问题(但是,当前解决此问题的方案是创建一个代理网络,以在代理服务之间存储和转发消息)。
代理服务发现
ActiveMQ 支持 自动发现 代理,可以使用 静态发现 或 动态发现。
因此,客户端可以从逻辑代理服务组中自动检测并连接到代理服务,也可以让代理服务发现并连接到其他代理服务以形成大型代理网络。
Discovery Agent
ActiveMQ 使用一个称为 Discovery Agent(发现代理)的抽象来检测远程服务,例如远程代理服务。
可以为 JMS 客户端使用 Discovery Agent 来自动检测要连接的消息代理 (Message Broker)或提供代理网络(Networks of Brokers)。
目前有两种 Discovery Agent:Multicast 和 Zeroconf,也支持 LDAP 发现
Multicast
发现传输使用ActiveMQ基于组播的发现代理来查找要连接的 URI 列表。更多信息见 Discovery Transport Reference,见下面 Discovery Transport 小节。
Zeroconf
ZeroConf 是一个标准发现规范,使用 UDP/组播来发现设备。 它被 Apple 的 Rendezvous 服务所用。
ActiveMQ 使用 jmDNS 来实现 Zeroconf 规 范来检测服务。这意味着另一个基于工具的 Zeroconf 可以与发现代理一起使用。
要在代理中启用发现,应使用 XML 配置,这里有一个使用发现创建代理网络的示例 > Github。
如果有一个或多个启用了 Zeroconf 发现的代理运行,则可以使用 brokerURL 连接到代理。
1 | zeroconf:_activemq_development. |
这将使用 Zeroconf 查找一个可用的代理,并随机选择一个且如果有多个代理正在运行,断开连接时将自动进行故障转移。
LDAP
ActiveMQ 支持使用 LDAP 来发现代理。详情见 LDAP Broker Discovery Mechanism 。
尝试发现
如果单独在外部运行以下命令,将有2个代理自动发现自己,并有2个使用固定 URL的客户端。
1 | maven -o server -Dconfig=src/test/org/activemq/usecases/receiver-zeroconf.xml |
如果希望客户使用发现来查找代理,运行上面的两个服务器语句之一(或同时运行两个),然后运行生产者/消费者,如下所示:
1 | maven -o consumer -Durl=zeroconf:_activemq.broker.development. |
传输的 URL格式为:
1 | zeroconf:<serviceName> |
其中<serviceName>是 Zeroconf 服务名称; 通常以下划线_开头,并且必须以点.结尾。 因此,可以使用此服务名称来区分 DEV,UAT 和 PRD 环境的代理(或将它们分组为域)等。
Discovery Transport
除了使用发现代理来查找要连接的 URI 列表以外,发现传输的工作方式与故障转移(Failover)传输相同。分列传输(Fanout)也使用发现传输来发现代理以向其发送分列消息。
配置语法:
1 | discovery:(discoveryAgentURI)?transportOptions |
注意:为了能够使用 Discovery 来查找代理,需要在代理服务上启用组播来发现代理。
要在 Broker 中配置发现,应该使用 XML 配置(/activemq-5.15.9/conf/activemq.xml)。这里有一个使用发现的示例 > Github。
如下是配置发现的示例,见 discoveryUri :
1 | <broker name="foo"> |
Options 配置项:
| 名称 | 默认值 | 描述 |
|---|---|---|
| reconnectDelay | 10 | 等待发现的时长 |
| initialReconnectDelay | 10 | 第一次尝试重新连接到发现的 URL 之前的等待时长(ms) |
| maxReconnectDelay | 30000 | 两次重新连接尝试之间的最大等待时长(ms) |
| useExponentialBackOff | true | 重新连接尝试之间是否开启幂系数 |
| backOffMultiplier | 2 | 幂系数值 |
| maxReconnectAttempts | 0 | 如果不等于 0,则表示重试连接的最大次数, 超过则返回异常到客户端。 |
URI 示例:
1 | discovery:(multicast://default)?initialReconnectDelay=100 |
将参数应用于发现的传输。
从 5.4 开始,如果 URI 中的传输参数以 discovered. 为前缀,则这些参数也将应用于发现的传输。
例如,向 URI 添加 discovered.connectionTimeout参数,将把该参数应用于每个发现的 TCP 传输,即使该参数不是 Discovery 传输配置选项。
Static Discovery
静态传输提供了一种硬编码机制,可以使用 URI 列表发现其他连接。使用此发现机制的连接将尝试连接到列表中的所有 URI,直到成功为止。
配置语法
1 | static:(uri1,uri2,uri3,…)?options** |
示例 URI:
1 | static:(tcp://localhost:61616,tcp://remotehost:61617?trace=false,vm://localbroker)?initialReconnectDelay=100 |
Options 配置项
| 名称 | 默认值 | 描述 |
|---|---|---|
| initialReconnectDelay | 10 | 第一次重新连接的等待时长(ms) |
| maxReconnectDelay | 30000 | 两次重新连接之间的最大间隔时长(ms) |
| useExponentialBackOff | true | 两次重新连接之间是否开启幂系数 |
| backOffMultiplier | 2 | 幂系数值 |
| maxReconnectAttempts | 0 | 如果不等于 0,则表示重试连接的最大次数, 超过则返回异常到客户端。 |
| minConnectTime | 500 | 创建连接最小时长,超过则认为连接失败 |
由于静态传输协议是用于代理发现的,因此客户端程序不应使用该协议。希望故障转移到代理实例的静态列表的客户端应改为使用 failover://transport。
Dynamic Discovery
动态代理发现参考 Discovery Transport Reference。参见上面的 Discovery Transport 小节。
代理服务网络
如果使用的是 Client / Server 或 Hub / Spoke (中心/分支)样式拓扑,并且有多个客户端和代理服务,则可能存在某个代理服务有生产者而没有使用者,则此代理服务中的消息不会堆积不被处理。
为避免此情况,ActiveMQ 支持代理网络(Networks of Brokers)。代理网络提供存储和转发功能,以将消息从存在生产者的代理服务中转移到有消费者的代理服务中,这使得可以在整个代理网络中支持分布队列(Queue)和主题(Topic)。
这允许客户端连接以任何代理,并在发生故障时转移到另一个代理服务(从客户端角度提供代理的高可用集群)。
在代理网络中可以灵活扩展大量的客户端,因为只要需要,可以运行大量的代理服务应用。
可以将代理网络视为具有自动故障转移和发现功能的客户端集群与代理服务集群的连接,从而使消息传递结构简单易用。
代理网络配置
配置代理网络的最简单方法是通过 Xml 配置 (/activemq-5.15.9/conf/activemq.xml)。 创建代理网络有两种主要方法:
- 使用
networkConnector元素的硬编码列表。 - 使用发现检测代理(多播或集合)。
静态 URI 列表方式示例:
1 |
|
ActiveMQ 还支持将 TCP 等其他传输方式用于网络连接器,例如 HTTP。
使用组播发现代理服务示例:
1 |
|
启动网络连接
默认情况下,网络连接器是作为代理启动序列的一部分顺序启动的。 若某些网络启动慢时,它们会阻止其他网络及时启动。
ActiveMQ 5.5 版支持代理属性networkConnectorStartAsync = true,这将导致代理使用执程序来并行启动网络连接器,与代理启动异步。
静态发现服务
使用 static:静态发现,可以对代理 URL 列表进行硬编码。 将为每个连接器创建一个网络连接器。如下:
1 | <networkConnectors> |
可以在静态网络连接器上设置一些有用的属性以进行重试:
| 属性 | 默认值 | 描述 |
|---|---|---|
| initialReconnectDelay | 1000 | 第一次重新连接前等待时长(ms) (useExponentialBackOff=false)。 |
| maxReconnectDelay | 30000 | 两次连接最大间隔时间(ms)。 |
| useExponentialBackOff | true | 是否开启重新连接等待时长指数系数 |
| backOffMultiplier | 2 | 增加等待时长的系数乘数 (useExponentialBackOff=true) |
示例:
1 | uri="static:(tcp://host1:61616,tcp://host2:61616)?maxReconnectDelay=5000&useExponentialBackOff=false" |
主从发现服务
代理服务通常会搭建 主 / 从 代理(一个主代理,至少一个从代理),需要实现主从之间的网络通信。
典型的配置涉及使用 failover:(故障转换),还需要增加一些其它配置才能使其工作。
ActiveMQ 5.6+ 提供了一个方便的发现代理(Discovery Agent),可以使用传输前缀masterslave:来指定。如下示例:
1 | <networkConnectors> |
URI 是按顺序列出:MASTER,SLAVE1,SLAVE2…SLAVE。
masterslave:的配置选项与 static: 相同。
网络连接器属性
参考 [Networks of Brokers > NetworkConnector Properties
代理网络消息可靠性
代理网络可以可靠地存储和转发消息。
如果源是持久队列或主题,则网络将提供持久性保证;如果源不是持久的,则网络无法增加持久性。
非持久性的主题和临时性的目标(Queues 和 Topics)都不持久。当非持久源是联网的,若发生网络故障,则可能丢失传输中的消息。
代理网络消息顺序
代理网络不能保证消息总的顺序。总的顺序适用于单个消费者,但 networkBridge 会引用第二个消费者。
此外,networkBridge 消费者通过 producer.send(...) 转发消息,因此消息从代理服务的队列的队头 转发到目标代理服务上的队列的队尾。
如果单个消费者在代理网络之间转移,则如果所有消息一直跟随该消费都,则可以保证消息总的顺序,但当出现大量的消息积压时,则很难保证总的顺序。
主从代理服务
网络中运行大量代理服务存在个问题:消息在任何时间点都由单个物理代理拥有。 如果该代理服务发生故障,则必须等待它重新启动才能传递消息(如果使用的是非持久消息传递,且代理崩溃,则通常会丢失消息)。
MasterSlave 是将消息复制到从属代理,这样,即使主代理服务发生灾难性的硬件故障时,也可以立即故障转移到从代理服务,而不会丢失消息。
目前有3种不同的主从配置模式:共享文件系统主从( Shared File System Master Slave),JDBC 主从( JDBC Master Slave),复制 LevelDB 存储(Replicated LevelDB Store)
Shared File System Master Slave
如果使用的是共享网络文件系统(如SAN),建议使用共享文件系统主从。
-
如果愿意放弃高性能日志并使用纯JDBC作为持久性引擎,那么应该使用JDBC主从。
-
对于愿意尝试新技术,复制的LevelDB存储提供了与SAN解决方案类似的速度,而无需设置高可用的共享文件系统。
复制消息存储
MasterSlave 的另一种方案选择是有某种方式来复制消息存储库,以便磁盘文件以某种方式共享。
例如,使用SAN或共享网络驱动器,可以共享代理的文件,这样,如果代理发生故障,另一个代理可以立即接管。
因此,通过支持复制消息存储(Replicated Message Store),可以降低消息丢失的风险,以提供能够在数据中心故障中幸存的高可用备份或完整的DR(Disaster Recover(灾难恢复))解决方案。
相关参考
MQ系列(二):ActiveMQ集群,独占消费者,消息组,消息顺序性
http://blog.gxitsky.com/2020/01/20/MQ-02-ActiveMQ-clusteing/