高并发之接口限流与实现
开发互联网系统及架构在满足测算出的并发请求时,还要预防并发可能突破设计峰值的情况,必要时可以优先处理高优先级数据或特殊特征的数据,也要确保系统可用不崩溃。
开发高并发系统时有三把利器用来保护系统:缓存、降级和限流。本文介结限流相关概念和实现方式。
限流概念
限流 的目的是通过对并发访问/请求进行限速或者一个时间窗口内的请求进行限速来保护系统,一旦达到限制速率则可以拒绝服务(定向到错误或告知资源没了),排队或等待(秒杀、评论、下单),降级(返回兜底数据或默认数据,如商品详情页库存默认有货)
另一层目的是通过限流来防止恶意请求,恶意攻击,或者防止流量超出系统峰值。原则上是限制流量穿透到后端薄弹的应用层。
常见的限流算法有:令牌桶算法、漏桶算法。计数器也可以用来进行粗暴的限流实现。
流量来源
流量来源主要有三种可能:
- 真实用户的请求流量。
- 爬虫的频繁请求,一般通过请求头,请求路径,静态资源加载来识别。
- 恶意请求,一般根据 IP 的请求频率,黑名单来做限制。
若恶意请求使用了大量的代理 IP,则不好识别,容易误伤真实用户。至于 DDoS 攻击,应归属于网络安全层面的了。
后面两种限流处理通常在 接入层(网关) 识别处理或在应用层处理之前拦截识别,还可以提前到负载均衡层处理(例如,Nginx deny 访问控制,limit 限流配置)。
可参考 Spring Boot 2实践系列(四十六):Spring AOP与拦截器实现API接口防刷。本文主要介绍大量的并发请求时的限流控制。
限流策略
常见的限流算法有:
- 限制总并发数(如 数据库连接池、线程池)
- 限制瞬时并发数(如 Nginx 的 limit_conn 模块)
- 限制时间窗口内的平均速率(如 Guava 的 RagteLimiter,Nginx 的 limit_req 模块,用来限制每秒的平均速度)
- 限制远程接口调用速率
- 限制 MQ 的消费速度
- 还可以根据 网络连接数,网络流量,CPU 或 内存负载等限流
限流算法
漏桶算法
概念
漏桶算法:一个固定容量的漏桶,桶中的水按照固定的速率流出,水流入的速率不受控制,如果流入的水超过桶的容量则溢出(丢度),桶容量不变。
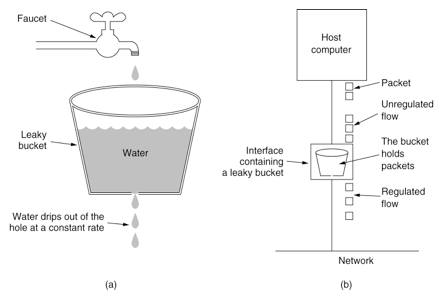
漏桶算法(Leaky Bucket)可以用于 流量整形 和 流量控制。漏桶算法可以控制流量输出端口的速率,平滑突发流量,实现流量整形,提供一个稳定的流量,是 强制限制数据的传输速率。
漏桶相当于一个容器,一个队列,应用只对存储在容器中的请求进行处理,溢出的请求则拒绝(抛弃或降级)。
漏桶算法的流出速率是固定的,对于需要处理突发性的流量来说是不满足的。
算法逻辑
下面方案二的思路:
桶的容量是固定的,要有桶的容量值:
int capacity。流出速率是固定的,要有流出速率的值:
float rate。需要定义一个桶中剩余的容量(配额):
int leftQuota要记录上一次漏水的时间:
long lastTime。根据速率计算漏掉的水数量:
leaked = (now - lastTime) * rate。若
leaked > 0则表示有流出,给lastTime = now赋值。计算桶中剩余的容量:
leftQuota = leftQuota + leaked若
leftQuota > capacity,则剩余配额最大只能等于桶容量,leftQuota = capacity假如入流量为
n,则剩余配额leftQuota = leftQuota - n,若leftQuota > 0表示可以处理,返回True,否则返回False
实现
方案一
计算桶中剩余的水量,如果小于容量,则处理业务
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47public class LeakyBucketLimiter {
public static void main(String[] args) throws InterruptedException {
LeakyBucket leakyBucket = new LeakyBucket();
for (int i = 0; i < 50; i++) {
boolean flag = leakyBucket.tryGet();
System.out.println(flag);
Thread.sleep(200);
}
}
/**
* 漏桶
*/
private static class LeakyBucket {
//桶中剩余水的数量
private volatile int water = 0;
//最近一次漏水时间
private volatile long lastTime = 0;
//桶的容量
private int capacity = 5;
//流出速率(时间毫秒)
private float rate = (float) 20 / (10 * 1000);
public boolean tryGet() {
long now = System.currentTimeMillis();
//时间段内总共漏出的水
int leaked = (int) ((now - lastTime) * rate);
if (leaked > 0) {
//表示在这期间有流出
lastTime = now;
}
//计算桶中剩余的水
water = Math.max(0, water - leaked);
if (water <= capacity) {
//如果没有溢出,添加当前一滴水,处理请求
water++;
return true;
}else {
//有溢出,拒绝请求
return false;
}
}
}
}测试结果:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20true
true
true
true
true
true
true
true
false
true
false
false
true
false
false
true
false
false
true
false方案二
另一种思路,计算可流入的水量(剩余配额),大于 0 则处理业务
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117/**
* 漏斗限流算法
*/
public class FunnelRateLimiter {
private Map<String, Funnel> funnelMap = new ConcurrentHashMap<>();
public static void main(String[] args) throws InterruptedException {
FunnelRateLimiter limiter = new FunnelRateLimiter();
int testAccessCount = 50;
//桶容量
int capacity = 5;
//每单个单位时间允许的流量
int allowQuota = 10;
//单位时间 秒
int perSecond = 30;
int allowCount = 0;
int denyCount = 0;
for (int i = 0; i < testAccessCount; i++) {
boolean isAllow = limiter.isActionAllowed("Tom", "doSomething", capacity, allowQuota, perSecond);
if (isAllow) {
allowCount++;
} else {
denyCount++;
}
System.out.println("访问权限:" + isAllow);
Thread.sleep(200);
}
System.out.println("报告:");
System.out.println("漏斗容量:" + capacity);
System.out.println("漏斗流动速率:" + allowQuota + "次/" + perSecond + "秒");
System.out.println("测试次数=" + testAccessCount);
System.out.println("允许次数=" + allowCount);
System.out.println("拒绝次数=" + denyCount);
}
/**
* 根据给定的漏斗参数检查是否允许访问
*
* @param username 用户名
* @param action 操作
* @param capacity 漏斗容量
* @param allowQuota 单位时间允许的流出量
* @param perSecond 单位时间(秒)
* @return 是否允许访问
*/
public boolean isActionAllowed(String username, String action, int capacity, int allowQuota, int perSecond) {
String key = "funnel:" + action + ":" + username;
if (!funnelMap.containsKey(key)) {
funnelMap.put(key, new Funnel(capacity, allowQuota, perSecond));
}
Funnel funnel = funnelMap.get(key);
return funnel.watering(1);
}
/**
* 漏斗对象
*/
private static class Funnel {
//容量
private int capacity;
//流出率
private float rate;
//剩余配额
private int leftQuota;
//上一次流出时间
private long lastTime;
public Funnel(int capacity, int allowQuota, int perSecond) {
//初始化桶容量
this.capacity = capacity;
//计算流出速率
this.rate = (float) allowQuota / (perSecond * 1000);
}
/**
* 漏斗漏水
*
* @param quota 流入量
* @return 是否有足够的水可以流出(是否允许访问)
*/
public boolean watering(int quota) {
//计算剩余配额
this.makeSpace();
int left = leftQuota - quota;
if (left >= 0) {
//还有剩余,则返回 true
leftQuota = left;
return true;
}
return false;
}
/**
* 根据上次水流动的时间,重新记算剩余空间
*/
private void makeSpace() {
long now = System.currentTimeMillis();
long times = now - lastTime;
//计算流出数量
int leaked = (int) (times * rate);
if (leaked < 1) {
//没有流出
return;
}
//剩余配额
leftQuota = leftQuota + leaked;
// 如果剩余大于容量,则剩余等于容量
if (leftQuota > capacity) {
leftQuota = capacity;
}
lastTime = now;
}
}
}
令牌桶算法
概念
令牌桶算法:以一个固定的速率往桶里放入令牌(Token),而如果请求需要被处理,则需要先从桶里获取一个令牌,当桶里没有令牌可取时,则拒绝服务。如果一段时间内没有请求,桶内就会堆积令牌,一次一旦有突发流量,只要令牌足够,就能一次处理。
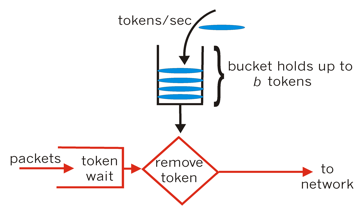
令牌桶算法是通过控制生成令牌的速率来控制请求流量,并允许突发流量。
假设请求速率是 10 request/second,令牌按照 5 个每秒的速率放入令牌桶。
放入令牌的速率通常设置为 QPS(queries per second),即每秒能处理的查询数。
桶的容量最多存放 20 个令牌,系统就只会允午每秒处理 5 个请求。
或等桶满 20 个令牌后,一次处理 20 个请求的突发情况。这样桶的容量就是系统能处理的最大并发数。
往桶里放入令牌的速率也是可以动过一些动态算法的实时计算来动态改变。
RateLimiter
**令牌桶算法 **的实现通常会借助 Google 的 Guava 库提供的限流工具类 RateLimiter,该类基于令牌桶算法(Token Bucket)来完成限流,易于使用。
Guava RateLimiter 提供的令牌桶算法可用于 平滑突发限流(SmoothBursty)和 平滑预热限流(SmoothWarmingUp)实现。
SmoothBursty(平滑突发限流)
RateLimiter create(double permitsPerSecond)使用,
RateLimiter rateLimiter = RateLimiter.create(10)默认是
SmoothBursty实现。创建一个具有稳定吞吐量的RateLimiter(令牌桶),指定每秒允许的许可证(令牌)数(通常为 QPS,每秒查询)。默认的RateLimiter配置可以保存最多一秒种的未使用许可证,即permitsPerSecond个许可证,这样就可以允许处理突发流量。rateLimiter.acquire()等同于
acquire(1)方法,获取 1 个许可证(令牌),如果没有则阻塞直到获取(消费)到令牌。也可以调用
double acquire(int permits)方法获取指定数量的许可证(令牌 ),成功获取令牌发放的速率。boolean tryAcquire()还可以调用
tryAcquire()方法来进行无阻塞或可超时的获取令牌。可以指定 获取令牌数,超时时间 和 时间单位。1
public boolean tryAcquire(int permits, long timeout, TimeUnit unit){.....}
SmoothWarmingUp(平滑预热限流)
SmoothBursty 允许一定程度的突发流量,若满峰值突然流量流入,系统可能扛不住。因此,可能需要一种平滑速率限制,从而使发放令牌的速度慢慢向平均固定速率平滑(即一开始速率小些,然后慢慢增加到固定速度),Guava 提供了 SmoothWarmingUp 来实现这种需求。
创建方式:RateLimiter create(double permitsPerSecond, long warmupPeriod, TimeUnit unit)。
- permitsPerSecond:每秒新增令牌数
- warmupPeriod:在达到稳定(最大)速率之前提高其速率的持续时间
测试平滑增速:
1 | public class SmoothWarmingUpLimiter { |
测试结果:
1 | 0.0 |
从测试结果可以看出,发放令牌的速率是逐渐上升(值越小,获取令牌等待时间越短,即发入令牌的速率越快),可以通过调整 warmupPeriod 参数实现平滑固定速率。
RateLimiter 与 java.util.concurrent.Semaphore(信号量)类似,只是 Semaphore 通常用于限制并发量。
实现
方案一:直接使用 Guava 的 RateLimiter,下面是使用及测试代码
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49public class TokenBucket {
public static void main(String[] args) throws InterruptedException {
//每秒新增 10 个令牌, 即每隔 100ms 新增一个令牌
final RateLimiter rateLimiter = RateLimiter.create(10);
//Thread.sleep(10000);
int maxNum = 50;
final CountDownLatch countDownLatch = new CountDownLatch(maxNum);
long startTime = System.currentTimeMillis();
for (int i = 0; i < maxNum; i++) {
Thread thread = new Thread(new Runnable() {
public void run() {
//获取(消费)一个令牌,有令牌则成功,返回 0,没有则暂停一段时间等待直到有令牌
//rateLimiter.acquire(5);//可以指令一次性消费的令牌数
rateLimiter.acquire();
System.out.println("RUN_TASK:" + Thread.currentThread().getName());
countDownLatch.countDown();
}
});
thread.setName("Name_" + i);
thread.start();
}
countDownLatch.await();
System.out.println("end takeTime" + (System.currentTimeMillis() - startTime));
/*CountDownLatch countDownLatch = new CountDownLatch(50);
ExecutorService executorService = Executors.newFixedThreadPool(50);
long startTime = System.currentTimeMillis();
for(int i=0; i<maxNum; i++){
executorService.submit(() -> {
try {
rateLimiter.acquire();
System.out.println("Thread:"+Thread.currentThread().getName());
countDownLatch.countDown();
} catch (Exception e) {
e.printStackTrace();
}
});
}
countDownLatch.await();
System.out.println("end takeTime:" + (System.currentTimeMillis() - startTime));*/
}
}方案二:自己实现一个简单的令牌桶
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57public class TokenBucketLimiter {
public static void main(String[] args) throws InterruptedException {
TokenBucket tokenBucket = new TokenBucket();
for (int i = 0; i < 20; i++) {
boolean flag = tokenBucket.tryAcquire();
System.out.println(flag);
Thread.sleep(150);
}
}
public static class TokenBucket {
private Lock lock = new ReentrantLock();
//当前桶中令牌个数
private volatile long token = 0;
//上次添加令牌的时间
private volatile long lastTime = 0;
//桶容量
private int capacity = 6;
//令牌放入桶中的速率 5/s
private int rate = 5;
public TokenBucket() {
}
public TokenBucket(int capacity, int rate) {
this.capacity = capacity;
this.rate = rate;
}
public boolean tryAcquire() {
lock.lock();
try {
long now = System.currentTimeMillis();
long between = now - lastTime;
//两次请求期间放入桶中的令牌数
long inTokens = ((now - lastTime) / 1000) * rate;
if (inTokens > 0) {
lastTime = now;
}
//计算桶中的令牌,与桶容量比较,取较小值
token = token + inTokens;
token = Math.min(token, capacity);
if (token > 0) {
token--;
return true;
}
} finally {
lock.unlock();
}
return false;
}
}
}测试结果:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20true
true
true
true
true
true
false
true
true
true
true
true
false
false
true
true
true
true
true
false
计数器算法
概念
计数器算法:统计一段时间内的总并发/总请求 是否超过限制,超过则拒绝请求,否则执行业务。使用数值类型的原子操作类实现增减操作。
计数器方式的限流是简单粗暴的,没有平滑处理。
实现
示意代码
1
2
3
4
5
6
7
8try {
if (atomic.incrementAndGet() > maxLimit) {
//拒绝请求;
}
//处理请求
} finally {
atomic.decrementAndGet();
}方案一:限制总并发
限制最大并发数为 5 个
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
public class UserController {
private final AtomicInteger atomic = new AtomicInteger(0);
private final static int MAX_LIMIT = 5;
public String queryUser() {
try {
if (atomic.incrementAndGet() > MAX_LIMIT) {
return "please try later";
}
//模拟执行业务耗时
Thread.sleep(200);
User user = new User().setUsername("Tom").setPassword("123456");
System.out.println(Thread.currentThread().getName() + " : " + System.currentTimeMillis());
return user.toString();
} catch (Exception e) {
e.printStackTrace();
} finally {
System.out.println(Thread.currentThread().getName() + ":" + atomic.get());
atomic.decrementAndGet();
}
return null;
}
}模拟 10 个并发线程
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
public class RunTest implements ApplicationRunner {
private static final Logger logger = LogManager.getLogger(RunTest.class);
private int maxThread = 10;
private RestTemplate restTemplate;
public void run(ApplicationArguments args) throws Exception {
System.out.println("执行多线程测试");
String url = "http://localhost:8080/user/query";
CountDownLatch countDownLatch = new CountDownLatch(1);
ExecutorService executorService = Executors.newFixedThreadPool(maxThread);
long startTime = System.currentTimeMillis();
for (int i = 0; i < maxThread; i++) {
executorService.submit(() -> {
try {
countDownLatch.await();
ResponseEntity<String> responseEntity = restTemplate.getForEntity(url, String.class);
System.out.println(Thread.currentThread().getName() + ":" + responseEntity.getBody());
} catch (Exception e) {
e.printStackTrace();
}
});
}
countDownLatch.countDown();
System.out.println("总耗时:" + (System.currentTimeMillis() - startTime));
}
}下面是测试客户端打印测试结果:
1
2
3
4
5
6
7
8
9
10
11
12执行多线程测试
:2
:please try later
:please try later
:please try later
:please try later
:please try later
:User(username=Tom, password=123456)
:User(username=Tom, password=123456)
:User(username=Tom, password=123456)
:User(username=Tom, password=123456)
:User(username=Tom, password=123456)下面是服务端接口打印测试结果:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15:6
:7
:6
:8
:8
: 1581168116253
:5
: 1581168116253
:4
: 1581168116253
: 1581168116253
:3
: 1581168116253
:2
:3从上面可以看出,计数大于最大限制并发数时,就直接返回了。
方案二:限制时间范围内的并发数
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
public class LimitController {
// 限流的并发数
private static int MAX_LIMIT = 10;
// 指定时间范围,单位秒
private static long interval = 20 * 1000;
// 原子类计数器
private final AtomicInteger atomic = new AtomicInteger(0);
//起始时间
private volatile long lastTime = System.currentTimeMillis();
public String getMst() {
long now = System.currentTimeMillis();
long micSecond = (long) (now - lastTime);
try {
if (atomic.incrementAndGet() > MAX_LIMIT && micSecond < interval) {
return "please try later";
} else if ((now - lastTime) > interval) {
lastTime = now;
atomic.set(1);
Thread.sleep(200);
User user = new User().setUsername("Tom").setPassword("123456");
System.out.println(">> :" + Thread.currentThread().getName() + " : " + micSecond);
return user.toString();
}
//模拟执行业务耗时
Thread.sleep(200);
User user = new User().setUsername("Tom").setPassword("123456");
System.out.println("== :" + Thread.currentThread().getName() + " : " + micSecond);
return user.toString();
} catch (Exception e) {
e.printStackTrace();
} finally {
atomic.decrementAndGet();
}
return null;
}
}
漏桶与令牌桶区别
- 漏桶算法:流出速率是固定的,流入速度不受控,当流入超过漏桶容量,则新流入的被丢弃。限流依赖的是流出速率是固定的,可以将突发流量平滑流出。
- 令牌桶算法:添加令牌到桶的速率是固定的,每次请求必须先拿到令牌,当桶中的令牌数为零时则拒绝新的请求(或阻塞等待直到获得令牌)。限流依赖的是固定流入速度,空闲时仍生成令牌放入桶中,这样就允许一定程度的突发流量。
信号量限制并发
通过 Semaphore 信号量来控制并发数。
示例
1 |
|
测试
并发测试受测试接口的响应时间和测试端的请求超时影响。
1 |
|
结果
1 | : 1581145238039 |
从测度结果可以看出,同一时刻最多只有三个线程进入。
应用级限流
限流总并发/连接/请求数
一个应用系统一定会有极限的并发/请求数,即 QPS/TPS 阀值,若超出阀值则可能响应很慢或不响应请求,最好是进行过载保护,以防止大并发压垮系统。
一些容器和组件支持并发线程数和等待线程数的控制。例如,Tomcat 的 Connector 项中就有一些参数可配置(server.xml)。
- maxThreads:线程池中最大的活动线程数,大并发请求时,Tomcat 能创建来处理请求的最大线程数,超过则放入请求队列中进行排队,默认为 200。
- acceptCount:最大排队线程数,超过这个值返回
connection refused,一般设置和maxThreads一样,默认值为 100。 - maxConnections:Tomcat 7 的属性,服务器在给定时间内将接受的最大连接数。
另外,如 MySQL(max_connections),Redis(tcp-backlog) 都会有类似的限制连接数的配置。
限制总资源数
对于稀有资源(如数据库连接,线程),可以使用池化技术来限制总资源数,如连接池,线程池,配置为系统能接收的最大值。超出则可以等待或抛出异常。
接口并发/请求限流
为防止接口突发高并发造成崩溃,可以限制接口的总并发/总请求数,粒度比较细,可以为每个接口设置相应的阀值。
在 Java 中可使用 AtomicLong 或 Semaphore 进行限流。Hystrix 的隔离策略中的 SEMAPHORE (信号量隔离)也是使用 Semaphore 限制接口的总并发数。见上的 计算器算法 小节。
适合对可降级业务或需过载保护的服务进行限流,如抢购业务,超出限额时,要么让用户排队,要么告诉用户没货。一些开放平台也可使用此方法限制接口调用的请求量。
时间窗请求数限流
即一个时间窗口内的请求数,如想限制某个接口 / 每秒 / 每分种 / 每天的请求数 / 调用量。
可以使用 Guava 的 Cache 来存储计数器,设置过期时间。然后获取当前时间戳,取秒数作为 key 进行计数统计和限流。
简单实现
添加 Guava 依赖
1
2
3
4
5<dependency>
<groupId>com.google.guava</groupId>
<artifactId>guava</artifactId>
<version>${guava_version}</version>
</dependency>创建API 接口
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
public class CacheLimiterController {
private LoadingCache<String, AtomicLong> loadingCache;
public void init() {
LoadingCache<String, AtomicLong> loadingCache = CacheBuilder.newBuilder()
.expireAfterWrite(2, TimeUnit.SECONDS)
.build(new CacheLoader<String, AtomicLong>() {
public AtomicLong load(String key) throws Exception {
return new AtomicLong(0);
}
});
this.loadingCache = loadingCache;
}
/**
* 2秒限制20次请求
*
* @throws ExecutionException
*/
public String cacheLimit() throws ExecutionException, InterruptedException {
long limit = 20;
long currentSeconds = System.currentTimeMillis() / 1000;
Thread.sleep(300);
if (loadingCache.get(String.valueOf(currentSeconds)).incrementAndGet() > limit) {
System.out.println("xxxxxxx限流了........." + "Second:" + currentSeconds + ", " + loadingCache.get(String.valueOf(currentSeconds)));
return "xxxxxxx限流了.........";
}
System.out.println("=======处理业务......." + "Second:" + currentSeconds + ", " + loadingCache.get(String.valueOf(currentSeconds)));
return "=======处理业务.........";
}
}多线程并发测试
使用前面的多线程测试代码,修改请求路径和线程数:
1
2private int maxThread = 30;
String url = "http://localhost:8080/limit/cache1";测试结果如下
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30:=======处理业务.........
:=======处理业务.........
:xxxxxxx限流了.........
:xxxxxxx限流了.........
:=======处理业务.........
:=======处理业务.........
:xxxxxxx限流了.........
:=======处理业务.........
:=======处理业务.........
:xxxxxxx限流了.........
:xxxxxxx限流了.........
:=======处理业务.........
:=======处理业务.........
:xxxxxxx限流了.........
:=======处理业务.........
:=======处理业务.........
:xxxxxxx限流了.........
:xxxxxxx限流了.........
:=======处理业务.........
:xxxxxxx限流了.........
:=======处理业务.........
:=======处理业务.........
:xxxxxxx限流了.........
:=======处理业务.........
:=======处理业务.........
:=======处理业务.........
:=======处理业务.........
:=======处理业务.........
:=======处理业务.........
:=======处理业务.........
AOP实现
在实际开发中,通常使用 AOP 或拦截器来统一处理接口限流。
添加依赖
1
2
3
4
5
6
7
8
9<dependency>
<groupId>com.google.guava</groupId>
<artifactId>guava</artifactId>
<version>28.2-jre</version>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-aop</artifactId>
</dependency>编写API接口限流注解
1
2
3
4
5
6
7
8
9
10
public ApiLimit {
/**
* 限流次数
* @return
*/
long times() default 20;
}将 Guava Cache 的 LoadingCache 注册为 Bean
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
public class GuavaCacheConfig {
public LoadingCache<String, AtomicLong> loadingCache() {
LoadingCache<String, AtomicLong> loadingCache = CacheBuilder.newBuilder()
.expireAfterWrite(2, TimeUnit.SECONDS)
.build(new CacheLoader<String, AtomicLong>() {
public AtomicLong load(String key) throws Exception {
return new AtomicLong(0);
}
});
return loadingCache;
}
}创建限流 AOP
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
public class APILimitAspect {
private static final Logger logger = LogManager.getLogger(APILimitAspect.class);
private HttpServletRequest request;
LoadingCache<String, AtomicLong> loadingCache;
public void pointcut(ApiLimit apiLimit) {
}
public void before(JoinPoint joinPoint, ApiLimit apiLimit) throws ExecutionException, IOException {
//限流次数
long times = apiLimit.times();
long currentSeconds = System.currentTimeMillis() / 1000;
RequestAttributes requestAttributes = RequestContextHolder.getRequestAttributes();
HttpServletResponse response = ((ServletRequestAttributes) requestAttributes).getResponse();
if (loadingCache.get(String.valueOf(currentSeconds)).incrementAndGet() > times) {
String msg = "xxxxxxx限流了........." + "Second:" + currentSeconds + ", " + loadingCache.get(String.valueOf(currentSeconds));
System.out.println(msg);
response.setCharacterEncoding("UTF-8");
response.setContentType("application/json;charset=UTF-8");
ServletOutputStream output = response.getOutputStream();
output.write(msg.getBytes("UTF-8"));
output.flush();
output.close();
}
}
}创建 API ,使用限流注解
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
public class CacheLimiterController {
private LoadingCache<String, AtomicLong> loadingCache;
public String cacheLimit2() throws InterruptedException {
System.out.println("=======开始处理业务.......");
Thread.sleep(200);
return "=======处理业务.........";
}
}多线程并发测试
使用前面多线程测试代码,修改请求路径和线程数。
1
2private int maxThread = 30;
String url = "http://localhost:8080/limit/cache2";测试结果如下
下面是测试端的打印
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30:xxxxxxx限流了.........Second:1581263996, 25
:xxxxxxx限流了.........Second:1581263996, 24
:xxxxxxx限流了.........Second:1581263996, 21
:xxxxxxx限流了.........Second:1581263996, 23
:xxxxxxx限流了.........Second:1581263996, 27
:xxxxxxx限流了.........Second:1581263996, 23
:xxxxxxx限流了.........Second:1581263996, 28
:xxxxxxx限流了.........Second:1581263996, 30
:xxxxxxx限流了.........Second:1581263996, 29
:xxxxxxx限流了.........Second:1581263996, 26
:=======处理业务.........
:=======处理业务.........
:=======处理业务.........
:=======处理业务.........
:=======处理业务.........
:=======处理业务.........
:=======处理业务.........
:=======处理业务.........
:=======处理业务.........
:=======处理业务.........
:=======处理业务.........
:=======处理业务.........
:=======处理业务.........
:=======处理业务.........
:=======处理业务.........
:=======处理业务.........
:=======处理业务.........
:=======处理业务.........
:=======处理业务.........
:=======处理业务.........
分布式限流
应用级的限流只适用于单体应用内的限流,不能进行分布式的全局限流。
现在稍上点规模的应用大多会分布式集群部署,应对高并发就需要实现分布式限流,分布式限流的关键是将限流服务做成原子化,解决方案可以使用 Redis + Lua 或 Nginx + Lua 技术来实现高并发和高性能。
Redis+Lua实现
借助 Redis 具有过期时间的特性,使用 Redis + Lua 实现时间窗口内某个接口的请求数限流。其实此方案与上面使用 Google Guava 实现时间窗口请求数限流是一样的,只是将应用内的 Guava 缓存替换成了可独立部署的 Redis 缓存,再通过 Lua 脚本来保证查询是原子操作。参考 Spring Boot 2实践系列(四十六):Spring AOP与拦截器实现API接口防刷。
下面基于 Spring Boot 实现限流,示例如下:
创建限流注解
1
2
3
4
5
6
7
8
9
10
public RedisLuaLimit {
/**
* 限流次数
* @return
*/
long limit() default 20;
}重新定义 RedisTemplate 序列化
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
public class RedisConfig {
public RedisTemplate<String, Object> redisTemplate(RedisConnectionFactory redisConnectionFactory) {
RedisTemplate<String, Object> template = new RedisTemplate<>();
template.setConnectionFactory(redisConnectionFactory);
FastJsonRedisSerializer serializer = new FastJsonRedisSerializer(Object.class);//2.35M
template.setKeySerializer(new StringRedisSerializer());
template.setValueSerializer(serializer);
template.setHashKeySerializer(new StringRedisSerializer());
template.setHashValueSerializer(serializer);
//开启事务支持
template.setEnableTransactionSupport(true);
template.afterPropertiesSet();
return template;
}
}创建 API 接口
在接口上使用限流注解
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
public class LimitController {
private RedisTemplate<String, Object> redisTemplate;
public String redisLimit() throws InterruptedException {
System.out.println("=======开始处理业务.......");
Thread.sleep(200);
return "=======处理业务.........";
}
}创建 AOP 统一前置处理接口限流
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
public class APILimitAspect {
private static final Logger logger = LogManager.getLogger(APILimitAspect.class);
private HttpServletRequest request;
private RedisTemplate<String, Object> redisTemplate;
public void pointcut(RedisLuaLimit redisLuaLimit) {
}
public void before(JoinPoint joinPoint, RedisLuaLimit redisLuaLimit) throws IOException {
//限流次数
long maxLimit = redisLuaLimit.limit();
long second = System.currentTimeMillis() / (1000);
String requestURI = request.getRequestURI();
String key = requestURI + ":" + String.valueOf(second);
RequestAttributes requestAttributes = RequestContextHolder.getRequestAttributes();
HttpServletResponse response = ((ServletRequestAttributes) requestAttributes).getResponse();
// ResourceLoader resourceLoader = new DefaultResourceLoader();
// Resource resource = resourceLoader.getResource("classpath:limit.lua");
ClassPathResource resource = new ClassPathResource("limit.lua");
String luaScript = Files.asCharSource(resource.getFile(), Charset.defaultCharset()).read();
RedisScript<Long> redisScript = new DefaultRedisScript<>(luaScript, Long.class);
List<String> keyList = new ArrayList<>();
keyList.add(String.valueOf(key));
//注意,传入 lua 脚本的所有参数都被认为是 String 类型, lua 脚本需要使有 tonumber() 转换
Long result = redisTemplate.execute(redisScript, keyList, maxLimit);
if (null != result && result == 0L) {
String msg = "xxxxxxx限流了........." + "Second:" + key;
response.setCharacterEncoding("UTF-8");
response.setContentType("application/json;charset=UTF-8");
ServletOutputStream output = response.getOutputStream();
output.write(msg.getBytes("UTF-8"));
output.flush();
output.close();
}
}
}创建 lua 脚本,放在资源路径根目录(
resources)下limit.lua
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15local key = KEYS[1]
local limit = ARGV[1]
local current = redis.call('get', key)
if (current) then
if tonumber(current) + 1 > tonumber(limit) then
return 0
else
redis.call("incrby", key, "1")
return 1
end
else
redis.call("set", key, "1")
redis.call("expire", key, "2")
return 2
end
Nginx+Lua实现
需要使用 lua-resty-lock互斥锁模块来解决原子性问题(在实际应用中需考虑获取锁的超时问题),并使用 ngx.shared.DICT共享字典来实现计数器。使用时需要先定义两个共享字典(分别用来存放锁和计数器)。
1 | local locks = require "resty.lock" |
nginx.conf 添加字典
1 | http { |
对这块的理解和开发,需要对 Nginx OpenResty 更详细的了解。
若并发量是特别特别巨大的,可以考虑通过一致性哈希将分布式限流进行分片,或降级为应用级限流。
接入层限流
接入层指请求流量的入口,该层通常具有 负载均衡,非法请求过滤,请求聚合,缓存,降级,限流,A/B测试,服务质量监控 等特性。
Nginx
对于分布式集群部署的应用,通常会使用 Nginx 来做接入层,限流可以使用 Nginx 自带的两个模块:连接数限流模块(ngx_http_limit_conn_module)和 漏桶算法实现的的请求限流模块(ngx_http_limit_req_module),还可以使用 OpenResty 提供的 Lua 限流模块(lua-resty-limit-traffic) 应对更复杂的限流场景。
limit_conn
使用 Nginx 自带的 ngx_http_limit_conn_module模块。
limit_conn 用来对某个 key 对应的总的网络连接数进行限流,可以按照 IP ,域名维度进行限流。不是每个请求连接都会被计数器统计,只有那些被 Nginx 处理的且已经读取了整个请求头的请求连接才会被计数器统计。
配置示例:
1
2
3
4
5
6
7
8
9
10
11
12http {
limit_conn_zone $binary_remote_addr zone=add:10m;
limit_conn_log_level error;
limit_conn_status 503;
.....
server {
.....
location /limit {
limit_conn add 1;
}
}
}- limit_conn:要配置存放 key 和计数器的共享内存区域和指定 key 的最大连接数。
上面示例指定的最大连接数为 1,表示 Nginx 最多同时并发处理 1 个连接。 - limit_conn_zone:用来配置限流 key 及存放 key 对应信息的典享内存区域大小。
此处的 key 是$binary_remote_addr,表示 IP 地址,也可以使用$server_name作为 key 来限制域名级别的最大连接数。 - limit_conn_status:配置被限流后返回的状态码,默认返回 503。
- limit_conn_log_level:配置记录被限流后的日志级别,默认 error 级别。
- limit_conn:要配置存放 key 和计数器的共享内存区域和指定 key 的最大连接数。
limit_conn 的主要执行过程
- 请求进入后首先判断当前 limit_conn_zone 中相应 key 的连接数是否超出了配置的最大连接数。
- 如果超过了配置的最大值,则被限流,返回 limit_conn_status 定义的错误状态码。否则相应 key 的连接数加 1,并注册请求处理完成的回调函数。
- 进行请求处理。
- 在结束请求阶段会调用注册的回调函数对应 key 的连接数减 1。
按照 IP 限制并发连接数配置示例
定义 IP 维度的限流区域
1
limit_conn_zone $binary_remote_addr zone=perip:10m
接着在要限流的 location 中添加限流逻辑
1
2
3
4location /limit {
limit_conn perip 2;
echo "123
}即允许每个 IP 最大并发连接数为 2.
使用 AB 测试工具进行测试,并发数为 5 个,总的请求数为 5 个。
1
ab -n 5 -c 5 http://localhost/limit
按照域名限制并发连接数配置示例
定义域名维度的限流区域
1
limit_conn_zone $server_name zone=perserver:10m;
在限流的 location 中添加限流逻辑。
1
2
3
4location /limit {
limit_conn perserver 2;
echo "123
}即允许每个域名最大并发请求连接数为 2。这样配置可以实现服务器最大连接数限制。
limit_req
使用 Nginx 自带的 ngx_http_limit_req_module模块。
limit_req 用来对某个 key 对应的请求的平均速率进行限流,有两种用法:平滑模式(delay) 和 允许突发模式(nodelay)。
limit_req 是漏桶算法实现,用于对指定 key 对应的请求进行限流。
limit-traffic
使用 OpenResty 提供了 Lua 限流模块 lua-resty-limit-traffic,可以实现更复杂的业务逻辑进行动态限流处理,可以根据实际情况变化 key ,速率,桶大小等动态特性来自定义实现。
其提供了 limit.conn 和 limit.req 实现,算法与 nginx limit_conn 和 limit_req 是一样的。
Zuul网关
对于使用 Sping Cloud 微服务框架,使用了 Zuul 做为网关组件的,可以使用 spring-cloud-zuul-ratelimit 库来实现限流。具体使用参考 Gihub > marcosbarbero/spring-cloud-zuul-ratelimit。