from langchain.tools import tool, ToolRuntime from langchain.agents import create_agent, AgentState from langgraph.types import Command from pydantic import BaseModel from langchain.messages import ToolMessage
# 调用智能体,传入用户名上下文 result = agent.invoke( {"messages": [{"role": "user", "content": "What is the weather in SF?"}]}, context=CustomContext(user_name="John Smith"), )
# 打印完整的消息历史 for msg in result["messages"]: msg.pretty_print()
输出:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16
================================ Human Message =================================
What is the weather in SF? ================================== Ai Message ================================== Tool Calls: get_weather (call_WFQlOGn4b2yoJrv7cih342FG) Call ID: call_WFQlOGn4b2yoJrv7cih342FG Args: city: San Francisco ================================= Tool Message ================================= Name: get_weather
The weather in San Francisco is always sunny! ================================== Ai Message ==================================
Hi John Smith, the weather in San Francisco is always sunny!
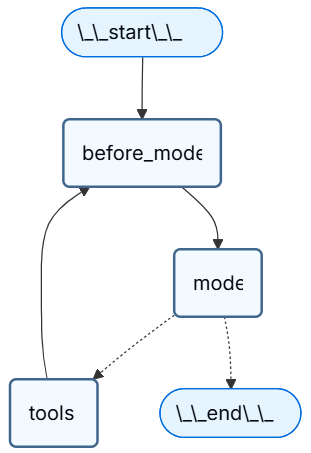
from langchain.messages import RemoveMessage from langgraph.graph.message import REMOVE_ALL_MESSAGES from langgraph.checkpoint.memory import InMemorySaver from langchain.agents import create_agent, AgentState from langchain.agents.middleware import before_model from langchain_core.runnables import RunnableConfig from langgraph.runtime import Runtime from typing importAny
# 多轮对话示例 agent.invoke({"messages": "hi, my name is bob"}, config) agent.invoke({"messages": "write a short poem about cats"}, config) agent.invoke({"messages": "now do the same but for dogs"}, config)
# 验证智能体是否还记得名字 final_response = agent.invoke({"messages": "what's my name?"}, config) final_response["messages"][-1].pretty_print()
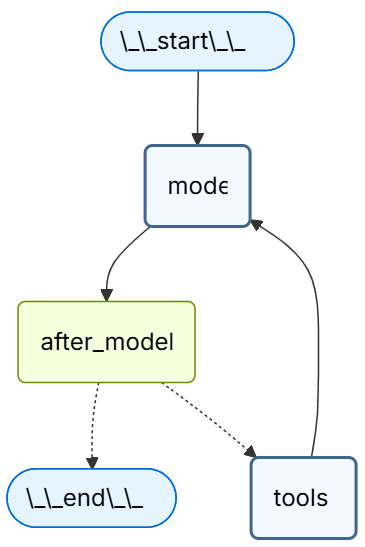
from langchain.messages import RemoveMessage from langgraph.checkpoint.memory import InMemorySaver from langchain.agents import create_agent, AgentState from langchain.agents.middleware import after_model from langgraph.runtime import Runtime
# 检查最后一条消息是否包含敏感词 ifany(word in last_message.content for word in STOP_WORDS): return {"messages": [RemoveMessage(id=last_message.id)]} # 删除该消息 returnNone